Początkowo wypuszczony był w październiku i dotyczył głównie języka angielskiego obejmując swym zasięgiem Stany Zjednoczone (US English). W najbliższych dniach przekonamy się, czy i jakie efekty przyniesie omawiana zmiana; czy przeniesienie wszystkich założeń z języka angielskiego sprawdzi się również u nas.
Spis treści:
1. Słowem wstępu
W internetowej społeczności seowców w ostatnim czasie pojawiło się sporo gifów i memów nawiązujących do postaci Berta (a czasem i Erniego) z Ulicy Sezamkowej.

źródło grafiki: https://www.seroundtable.com/google-bert-update-28427.html
Wszystko to spowodowane jest informacją, jaką opublikowało Google na swoim blogu 25.10.2019 (https://www.blog.google/products/search/search-language-understanding-bert/), która dotyczyła kolejnej już aktualizacji algorytmu, która wpłynie szacunkowo na 10% zapytań w wynikach wyszukiwania. Oprócz tego obejmie swym zasięgiem również polecane fragmenty z odpowiedzią (featured snippets) w krajach, gdzie dotychczas były dostępne.
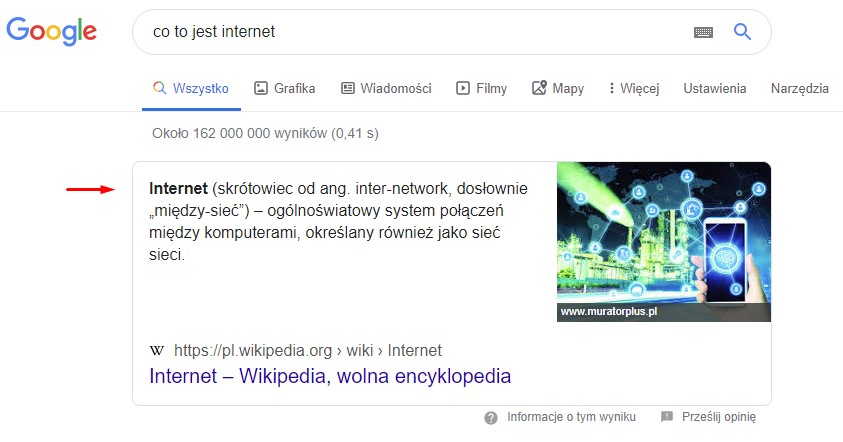
Przykład fragmentu z odpowiedzią (featured snippet) w porównaniu do odpowiedzi bezpośrednich (direct answers) – podstawowa różnica to występowanie linku w wyniku.
Wspomniana aktualizacja nosi nazwę Google BERT (stąd konotacje z muppetem Bertem). Google opisuje BERTa jako największą zmianę w systemie wyszukiwania od czasu wprowadzenia prawie pięć lat temu RankBraina, a nawet jedną z największych zmian algorytmicznych w historii wyszukiwania. Informacja o „przybyciu” BERTa i jego zbliżającym się wpływie wywołała niemałe poruszenie w społeczności SEO. Wraz z tym poruszeniem pojawiły się również pewne niejasności co do tego, co właściwie robi BERT, jak działa i co to oznacza dla całej branży. Poniżej postaramy odpowiedzieć na te pytania.
AKTUALIZACJA 10.12.2019:
Google ogłosiło na Twitterze, że ich algorytm BERT jest obecnie wdrażany na całym świecie. Pozwoli on lepiej zrozumieć wyszukiwane hasła w ponad 70 językach (w tym także w języku polskim):
BERT, our new way for Google Search to better understand language, is now rolling out to over 70 languages worldwide. It initially launched in Oct. for US English. You can read more about BERT below & a full list of languages is in this thread.... https://t.co/NuKVdg6HYM
— Google SearchLiaison (@searchliaison) December 9, 2019
Hebrew, Hindi, Hungarian, Icelandic, Indonesian, Italian, Japanese, Javanese, Kannada, Kazakh, Khmer, Korean, Kurdish, Kyrgyz, Lao, Latvian, Lithuanian, Macedonian
— Google SearchLiaison (@searchliaison) December 9, 2019
Malay (Brunei Darussalam & Malaysia), Malayalam, Maltese, Marathi, Mongolian, Nepali, Norwegian, Polish.... (MORE)
2. Czym jest BERT?
BERT jest przełomowym technicznie modelem służącym do przetwarzania języka naturalnego, który podbija świat odkąd został wydany w postaci pracy naukowej napisanej przez Jacoba Devlina i współtwórców (Min-Wei Chang, Kenton Lee, Kristina Toutanova; https://arxiv.org/abs/1810.04805) w 2018 r. Zespół Google AI Research ogłosił późniejszą papierową publikację BERTa jako wkład typu open source (https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html), a rok później ogłoszono wspomnianą aktualizację algorytmiczną. Google podkreśla znaczenie BERTa dla kontekstowego rozumienia języka w kontencie (zawartości strony) i zapytaniach.
BERT (z języka angielskiego Bidirectional Encoder Representations from Treansformers) to wstępnie przeszkolona platforma do nauki języka naturalnego, która jeszcze na etapie badań dała najnowocześniejsze wyniki w przetwarzaniu 11 przydzielonych zadań językowych. Zadania te obejmują między innymi oznaczanie ról semantycznych, klasyfikację tekstu, przewidywanie kolejnego zdania etc. BERT pomaga również w ujednoznacznieniu słów polisemicznych w kontekście. Pierwotnie był wyszkolony na całej angielskiej Wikipedii i na zbiorze dzieł związanych ze współczesnym j. ang. Uniwersytetu Brown.
Meet BERT, a new way for Google Search to better understand language and improve our search results. It's now being used in the US in English, helping with one out of every 10 searches. It will come to more counties and languages in the future. pic.twitter.com/RJ4PtC16zj
— Google SearchLiaison (@searchliaison) October 25, 2019
Jest nie tyle jednorazowa zmianą algorytmiczna, co podstawową warstwą, pomocną w zrozumieniu i ujednoliceniu niuansów językowych w zdaniach, frazach; ma się ciągle udoskonalać w każdym szczególe.
3. Geneza BERTa
3.1. Wyzwanie, jakie stawia nam język naturalny
Zrozumienie sposobu, w jaki słowa pasują do struktury i znaczenia to działka nauki związana z językoznawstwem. Rozumienie języka naturalnego (NLU, NLP) sięga lat 60. XIX wieku, może nawet wcześniej, kiedy to definiowano, czym jest AI (Artificial Intelligence, sztuczna inteligencja). Boryka się z nierozwiązanymi problemami dotyczącymi niejednoznaczności języka (niejasności leksykalne). Niemal co drugie słowo w języku angielskim posiada wiele znaczeń. Podobnie sytuacja wygląda w innych językach.
Prowadzi to do naturalnej sytuacji, że w bazie tworzy się ciągle rosnąca sieć treści, rozbudowywana w trakcie każdej podjętej przez wyszukiwarki próby interpretacji zamiarów użytkownika. Dotyczy to zarówno zapytań wpisywanych ręcznie, jak i głosowych.
23.2. Niejasności leksykalne
W lingwistyce, dwuznaczność dotyczy bardziej zdania niż poziomu słowa. Słowa o wielu znaczeniach łączą się, by stworzyć wieloznaczeniowe zdania i frazy, które stają się trudniejsze do zrozumienia. Według Stephena Clarka (https://www.cam.ac.uk/research/features/our-ambiguous-world-of-words), który był wcześniej związany z Uniwersytetem w Cambridge, a obecnie pełnoetatowego badacza w Deepmint:
„Niejednoznaczność jest największym przewężeniem („wąskim gardłem”) w trakcie zdobywania wiedzy obliczeniowej, zabójczym problemem wszystkich procesów przetwarzania języka naukowego.”
W poniższym przykładzie zaczerpniętym z WordNet (leksykalnej bazie grupującej angielskie słowa w zbiory synonimów; http://wordnetweb.princeton.edu/perl/webwn?s=BASS), widzimy, że słowo „bass” ma wiele znaczeń, spośród których kilka odnosi się do muzyki i tonów, a niektóre z nich mają konotacje z rybami. Co więcej, w przypadku kiedy słowo „bass” wiąże się znaczeniowo z muzyką, może ono występować jako rzeczownik oraz jako przymiotnik, co bardziej komplikuje sprawę.
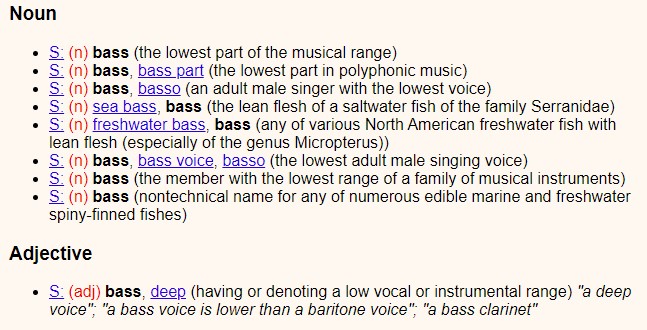
Polisemia i homonimia
Słowa z wieloma znaczeniami kategoryzowane są jako polisemiczne lub homonimiczne:
Słowa polisemiczne to takie z dwoma znaczeniami lub większą ich ilością. Korzenie tych znaczeń są jednego pochodzenia, a same znaczenia różnią się od siebie delikatnie, różnice pomiędzy mini to jedynie niuanse. Świetnym przykładem z języka angielskiego może być czasownik „run”, który jest polisemiczny i stanowi największy wpis w „Oxford English Dictionary” – posiada aż 606 różnych znaczeń (https://www.oxfordlearnersdictionaries.com/definition/english/run_1). Przykład polisemów w języku polskim: język (organ, mowa ludzka), szkoła (instytucja, budynek).
Homonimy to kolejny rodzaj słów z mnogą liczbą znaczeń, jednak opierają się one mniej na niuansach, a bardziej na konkretach. Posiadają taki sam zapis, a ich znaczenia są często zgoła różne. Przykład homonimów w języku polskim: orka (oranie ziemi, gatunek delfina), bal (kłoda drewna, zabawa taneczna). Jak widać, oba znaczenia homonimu nie mają ze sobą jakiegokolwiek powiązania.
Homografy i homofony
Kolejne podkategorie homonimów jeszcze bardziej gmatwają całą sytuację i nie ułatwiają wyszukiwarce zrozumienia naturalnego języka. Słowa, które mają taki samo brzmienie, inny zapis, a różne znaczenie to homofony. Słowa, które są różnie zapisywane, ale brzmią tak samo to homofony. Język angielski, od którego zaczęło się przeprowadzane badanie, jest szczególnie problematyczny, jeśli mowa o homofonach. wymienić można ponad 400 przykładów homofonów angielskich (http://www.singularis.ltd.uk/bifroest/misc/homophones-list.html), a przykładowe z nich to:
- made/maid;
- for/fore/four;
- there/their;
- where/whear/were.
Przykład homofonu w języku polskim: zmorzony/zmożony (zmęczony/pokonany), dróżka/drużka (wąska droga/druhna).
Istnieją również frazy, które zazwyczaj nie są kojarzone z homofonią, a zestawione ze sobą staja się podobnie brzmiące mimo zupełnie innego znaczenia. Przykładem mogą tu być frazy „four candles” i „fork handles”. Jeśli rozdzielić oba słowa, nie są to frazy homofoniczne, jeśli jednak wypowiedziane łącznie, brzmią prawie identycznie. Podobne zestawienia mogą być problematyczne nie tylko dla maszyn analizujących naturalny język (wyszukiwanie konwersacyjne, conversational search), ale również dla ludzi.
Synonimy są inne
Dla wyjaśnienia, synonimy odróżniają się od polisemów i homonimów. Synonimy oznaczają to samo lub coś podobnego, są jednak odrębnymi słowami. Dobrym przykładem będą tutaj przymiotniki „niewielki”, „drobny”, „mini” jako synonimy słowa „mały”. Mogą one powodować kolejne problemy przy analizie tekstu przez AI.
Zaimki
Zaimki, jak „oni”, „on”, „to”, „ich”, „ona” itp. mogą również być bardzo problematycznym wyzwaniem w zrozumieniu naturalnego języka. Łatwo jest zgubić wątek odnośnie tego, do czego odnosi się dany zaimek w kolejnych zdaniach i akapitach. To wyzwanie językowe stawiane prze zaimki określa się jako rozdzielczość korelacji i może odnosić się do tego, co było wcześniej wspominane w tekście (anafora), a także do tego, o czym dopiero będzie mowa (katafora). Pojmować to można jako po prostu „możliwość śledzenia” tego, o czym/kim jest aktualnie mowa w tekście. Poniżej opisujemy dokładniej dlaczego katafora i anafora mogą być problematyczne dla AI.
Anafora i katafora (anafora resolution, cataphora resolution)
Anafora jest wyrazem, który odnosi się do obecnego elementu wypowiedzi. Przykład: Wczoraj na zajęciach korzystaliśmy z komputerów. To było bardzo ciekawe.
Katafora jest wyrazem odnoszącym się do tego, co dopiero nastąpi w wypowiedzi. Przykład: Tam nie wolno wchodzić. W dole leży niewypał.

3.3. Ludzie a wieloznaczność
Ludzie w większości nie przejmują się wyżej opisanymi leksykalnymi wyzwaniami w rozdzielczości korelacji i polisemii. Nie muszą się tym przejmować, ponieważ posiadają dozę zdroworozsądkowego i podświadomego rozumienia, które kształtujemy od dzieciństwa. Rozumiemy, do czego odnoszą się zaimki „ona” lub „oni” podczas czytania wielozdaniowych akapitów lub słuchania rozmów, ponieważ bez problemu śledzimy, kto/co jest przedmiotem uwagi.
Automatycznie zdajemy sobie sprawę - gdy na przykład słyszymy zdanie zawierające różne powiązane tematycznie słowa, jak „ślub”, „bukiet”, „pan młody” itp. – że chodzi tu o „drużkę”, nie „dróżkę”. Porządkując słowa, jesteśmy świadomi kontekstu, w którym są one wypowiadane lub pisane. Dlatego jesteśmy w stanie stosunkowo łatwo poradzić sobie z dwuznacznością i niuansami z nią związanymi.
3.4. Maszyny a wieloznaczność
Maszyny nie rozumieją automatycznie kontekstowych połączeń słowa, by jednoznacznie rozróżnić znaczenia „dróżki i „drużki”. Tym bardziej biorąc pod uwagę słowa z większą ilością znaczeń niż tylko 2. Maszyny łatwo tracą orientację, o kim mówi się w zdaniach więc rozdzielczość korelacji (coreference resolution) również jest poważnym problemem.
3.5. Jak wyszukiwarki internetowe uczą się języka
Jak więc lingwiści i badacze wyszukiwarek internetowych umożliwiają maszynom jednoznaczne zrozumienie znaczenia słów zwrotów, zdań w języku naturalnym? „Czy nie byłoby dobrze, gdyby Google rozumiało znaczenie twojego zdania, a nie tylko słowa w nim zawarte?” – powiedział Eric Schmidt z Google w 2009 r. (https://www.pcworld.com/article/161869/google_intros_semantic_search.html), tuż przed tym, jak firma ogłosiła wdrożenie w wyszukiwarce swoich pierwszych semantycznych podpowiedzi (https://googleblog.blogspot.com/2009/03/two-new-improvements-to-google-results.html).
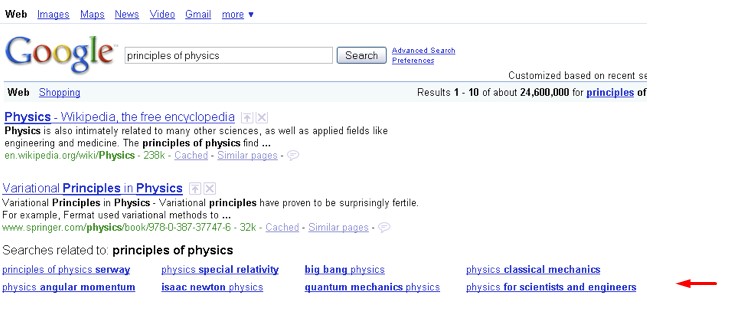
To sygnalizowało jeden z pierwszych ruchów sugerujących odejście od wcześniejszego stanowiska „strings to things”, bardziej zerojedynkowego. Eric Schmidt wspomina o „powiązanych” wynikach pokazywanych jak na screenie wyżej. Przy wpisaniu frazy „principles of physics” (podstawy fizyki) uzyskiwał on takie podpowiedzi, jak „angular momentum” (moment pędu), „big bang” (wielki wybuch), „quantum mechanic” (mechanika kwantowa) czy też „special relativity” (szczególna teoria względności). Podpowiedzi te mogły być brane pod uwagę jako współwystępujące w naturalnym języku ze względu na powiązania tematyczne. Powiązania mogą być nikłe, jednak istnieje prawdopodobieństwo znalezienia ich w treści jednej strony.
Jak więc wyszukiwarka łączy takie powiązane frazy? Na jakiej zasadzie pokazuje „wyszukiwania podobne do” znajdujące się pod SERPami?
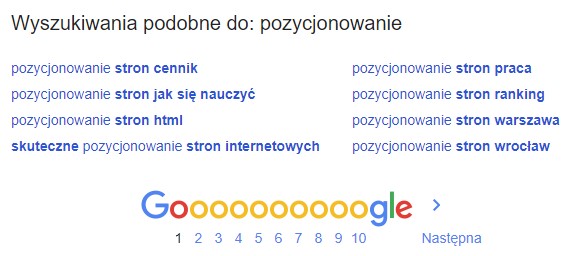
Współwystępowanie
W lingwistyce komputerowej współwystępowanie jest zgodne z ideą, że słowa o podobnym znaczeniu mają tendencję do tego, by były używane w pobliżu siebie w języku naturalnym. Innymi słowy, zwykle znajdują się one w bliskim sąsiedztwie w zdaniach i akapitach. Ta dziedzina badań związków międzywyrazowych i ich współwystępowania nazywana jest „Firthian Linguistics” (http://www.lel.ed.ac.uk/homes/patrick/firth.pdf), a jej początki są zwykle wiązane z lingwistą lat 50. XIX wieku, Johnem Firthem (https://en.wikipedia.org/wiki/John_Rupert_Firth), znanym ze słów:
You shall know a word by the company it keeps.
Podobieństwa i pokrewieństwa
W lingwistyce wg Firtha słowa i pojęcia egzystujące razem w pobliskich przestrzeniach tekstu są podobne i powiązane. Słowa, które są podobnymi „rodzajami rzeczy”, mają podobieństwo semantyczne. Dla przykładu samochód i autobus mają podobieństwo semantyczne, ponieważ oba są rodzajem pojazdu.
Pokrewieństwo odróżnia się od podobieństwa semantycznego. Samochód jest podobny do autobusu ze względu na to, że oba są pojazdami. Dodatkowo, samochód połączony jest z „drogą” czy „kierowaniem”. Można się spodziewać tego, że samochód zostanie wspomniany na stronie o drodze i kierowaniu lub też innej linkowanej tam witrynie. Ludzie w naturalny sposób rozumieją to współwystępowanie, podobnie, jak w przypadku wcześniej wspomnianego przykładu z drużką/dróżką.
Szerzej szczegóły dotyczące podobieństwa i pokrewieństwa w języku naturalnym omawiane są w tym wideo:
Grafy Wiedzy (Knowledge Graphs) i repozytoria
Kiedykolwiek wspomniane jest wyszukiwanie semantyczne, prawdopodobnie automatycznie myślimy o grafach wiedzy pojawiających się w Google, a także o danych strukturalnych, jednak NLU nie jest temu równoznaczne. Niemniej jednak dane uporządkowane ułatwiają wyszukiwarkom zrozumienie języka naturalnego. Ujednoznaczniają dany temat. Łączą go z innymi słowami i kategoryzują. Dla przykładu, kiedy w tekście wspomniane jest słowo „Mozart”, może ono odnosić się do kompozytowa, kawiarni czy też ulicy o tej nazwie. Dopiero towarzystwo innych słów daje możliwość dokładnego skategoryzowania słowa wyszukiwarce.
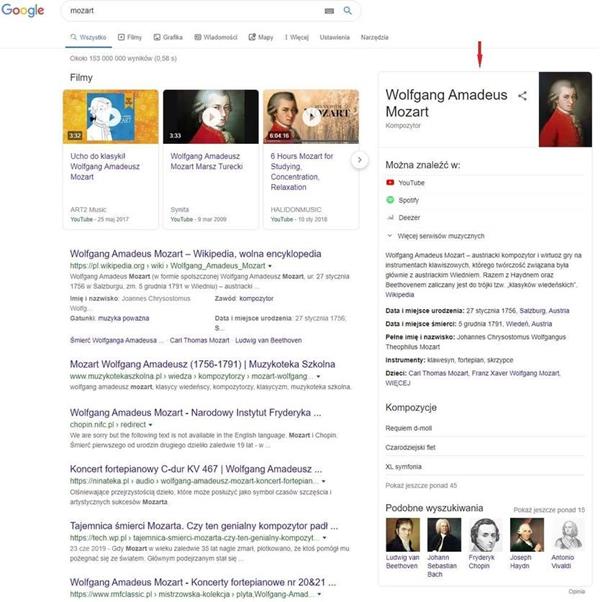
Większość zawartości w sieci w ogóle nie jest ustrukturyzowana np. przy wykorzystaniu schematów Schema.org. AI przy rozpatrywaniu całego internetu bierze zatem pod uwagę nawet semi-strukturalne elementy takie jak: nagłówki, wypunktowane i numerowane listy, dane zawarte w tabelach i sporo innych. W takich treściach pojawia się też sporo „wolnego”, nieustrukturalizowanego tekstu, który może być rozumiany niejednoznacznie. NLP polega na przetwarzaniu tego „wolnego” tekstu w zdaniach, frazach i akapitach; oddzielaniu go od tego, co już zostało zaklasyfikowane (the entities). W zrozumieniu tych pozostałych treści pomocne są również wspomniane wcześniej podobieństwo i pokrewieństwo słów.
Oznaczanie części mowy
Inna ważna część lingwistyki komputerowej zaprojektowanej do uczenia się naturalnych połączeń w języku ludzkim dotyczy mapowania słów na poszczególne części mowy: rzeczowniki, przymiotniki, czasowniki, zaimki, etc. Niektórzy współcześni lingwiści rozszerzyli kategoryzowanie części mowy z tych podstawowych na bardziej szczegółowe, jak na przykład: czasownik w liczbie pojedynczej i innej niż trzeciej osobie w czasie teraźniejszym, czasownik w trzeciej osobie i liczbie pojedynczej w czasie teraźniejszym, zaimek dzierżawczy i in. W ten sposób z małej liczby części mowy tworzy się ich spora ilość – anglojęzyczne źródła przytaczają w tym przypadku 2 przykłady klasyfikacji takich części mowy: The Penn Treebank Tagger z 36 (https://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos.html) częściami mowy oraz CLAWS7 z 146 częściami mowy (http://ucrel.lancs.ac.uk/claws1tags.html). W Polsce również opracowano różne klasyfikacje części mowy, np. wg Saloniego<.
Bezpośrednio w Google oznaczaniem części mowy zajmuje się ekipa lingwistów Google Pygmalion (https://www.wired.com/2016/11/googles-search-engine-can-now-answer-questions-human-help/). Pracuje ona nad wyszukiwaniem głosowym oraz asystentem. Pygmalion wykorzystuje przytoczony tu sposób oznakowywania części mowy do trenowania AI, by lepiej odpowiadała w postaci wspomnianych już np. featured snippets.
Rozumienie części mowy w danym zdaniu pozwala maszynie, w jaki sposób działa ludzki język. Dla zobrazowania można skorzystać z narzędzia rozpoznającego anglojęzyczne części mowy: https://parts-of-speech.info/.
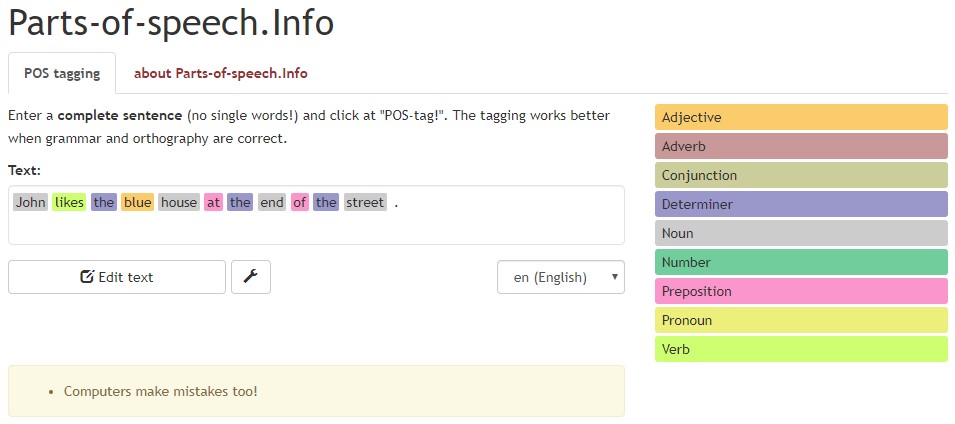
Każda z części mowy oznaczona jest osobnym kolorem. Nie byliśmy w stanie odnaleźć analogicznego narzędzia w języku polskim, jeśli jednak je znasz – daj nam znać, a zaktualizujemy treść artykułu.
Problemy z metodami NLU
Pomimo wielkiego postępu w wyszukiwarkach internetowych i lingwistyce komputerowej, występuje szereg niedociągnięć uniemożliwiającym maszynom całkowite zrozumienie języka ludzkiego oraz prawidłowe przeskalowanie wykorzystywanych metod na inne języki niż tylko angielski. Poniżej wymieniamy jedynie wybrane z problemów związanych z NLU.
- Pygmalionu nie można przeskalować na inne języki
Wspomniana wcześniej klasyfikacja części mowy może okazać się czasochłonna oraz kosztowna. Co więcej, ludzie nie są doskonali, dlatego często występują błędy oraz spory. To, do jakiej części mowy zaklasyfikować dane słowo w wybranym kontekście może doprowadzić lingwistów do godzinnych konwersacji. Zespół lingwistów Google składał się w 2016 roku z około 100 wykształconych specjalistów związanych z językoznawstwem.
W wywiadzie dla magazynu Wired (https://www.wired.com/2016/11/googles-search-engine-can-now-answer-questions-human-help/) David Orr, kierownik produktu w Google, wytłumaczył, dlaczego jego zespół w dalszym ciągu potrzebuje szeregu specjalistów tagujących konkretne słowa jako poszczególne części mowy. Nazwał to „złotymi” danymi, które pomagają AI zrozumieć zasady działania ludzkiego języka.
Orr powiedział o Pygmalionie:
„Zespół opracowuje od 20 do 30 języków. Mamy jednak nadzieję, ze firmy takie, jak Google będą mogły ostatecznie przejść na bardziej zautomatyzowaną formę sztucznej inteligencji, nienadzorowane uczenie AI.”
Do roku 2019 zespół Pygmalionu był już spora grupą 200 lingwistów z całego świata – zarówno stałych pracowników, jak i agencyjnych. Nie brakowało pracy dla nich wszystkich ze względu na pracochłonny i zniechęcający charakter ręcznego tagowania i związanych z tym długich godzin pracy.
W tym samym artykule dla Wider Chris Nicholson (założyciel firmy Skymind) skomentował niedoskonałą naturę projektów takich jak Google Pygmalion. Podkreślił też perspektywę międzynarodową, która będzie problematyczna – jeśli chce być naprawdę wielojęzyczna, to część tagowania części mowy musiałaby zostać wykonana przez lingwistów specjalizujących się w każdym języku świata.
- Jednokierunkowy sposób czytania tekstu a jego spójność
Modele szkoleniowe AI (np. Skip-gram i Continuous Bag of Words) są jednokierunkowe. W wielkim uproszczeniu, zdania są czytane linearnie. Następne słowa nie są jeszcze widoczne dla maszyny, nie widzi ona całego kontekstu zdania i nie zrozumie go dopóki nie dotrze do ostatniego słowa. Niesie to ze sobą prawdopodobieństwo, że zostaną pominięte niektóre wzory pojawiające się w kontekście całej zawartości danej strony.
Zapisz się na newsletter i bądź na bieżąco z naszymi artykułami. Nie przegap najciekawszych tekstów.
Administratorem udostępnionych przez Ciebie danych osobowych jest Ideo Force Sp. z o.o. Podanie danych osobowych jest dobrowolne, jednak ich niepodanie uniemożliwi świadczenie usług na Twoją rzecz. Dowiedz się więcej o zasadach przetwarzania Twoich danych osobowych oraz przysługujących Ci uprawnieniach w Polityce prywatności.
Taka jednokierunkowość powoduje, że tekst nie jest spójny. Często najdrobniejsze słowa robią wielką różnice i stanowią o całym oddźwięku tekstu, właśnie o jego spójności. Ważny jest temat zdania, akapitu, czy całego tekstu, a także sam szyk zdań – kolejność pojawiania się poszczególnych wyrazów. Oprócz tego, jak wspominaliśmy już w artykule, lingwiści mogą mieć problemy z odpasowaniem danego słowa do konkretnej części mowy. Jeszcze innym problemem może być pojawienie się wyrażeń idiomatycznych, w których każde słowo z osobna znaczy zupełnie co innego niż wszystkie razem.
Nieco lepsze w rozumieniu kontekstu były późniejsze modele szkoleniowe AI, jak np. ELMo, które czytały zawartość na lewo i na prawo od danego słowa kluczowego. Robiły to jednak niejednocześnie, co również nie oddawało w pełni prawdziwego kontekstu.
4. Jak BERT pomaga wyszukiwarce lepiej zrozumieć język?
Biorąc pod uwagę wszystko, co do tej pory opisaliśmy, postaramy się odpowiedzieć na pytanie dotyczące wpływu BERTa na wyszukiwarki internetowe (i in.) i ich rozumienie języka ludzkiego.
Just checking that BERT is working OK. Says he's good. pic.twitter.com/qUSzQxpfLD
— Danny Sullivan (@dannysullivan) November 1, 2019
Dlaczego BERT jest tak wyjątkowy? Kilka elementów sprawia, że BERT jest tak wyjątkowy dla wyników wyszukiwania. Część z nich zawarta jest w nazwie (np. dwukierunkowość, Bi-Directional), są też inne zmiany, które wprowadza:
4.1. Przeszkolenie w czytaniu tekstu nieotagowanego ręcznie
„Magią” BERTa jest wdrożenie dwukierunkowej metody czytania na tekście, który nie był otagowany ręcznie przez lingwistę. Był pierwszym frameworkiem naturalnego języka, który został wstępnie przeszkolony do analizowania nieotagowanego ręcznie, czystego tekstu (2.5 miliarda słów z angielskiej Wikipedii) bez nadzoru. Wszystkie wcześniejsze modele analizy języka wymagały, by tekst został ręcznie oznaczony.
BERT uczy się języka poprzez przyswajanie spójności pojawiających się w zanalizowanym tekście. Zostaje później bardziej drobiazgowo edukowany na mniejszych porcjach przykładach z języka naturalnego. Z czasem zaczyna uczyć się sam.
4.2. Wspomniana dwukierunkowość
BERT to pierwszy prawdziwie dwukierunkowy model NLP. Co to jednak oznacza? Prawdziwe zrozumienie kontekstowe wynika z możliwości jednoczesnego zobaczenia wszystkich słów w zdaniu i zrozumieniu, w jaki sposób wszystkie te słowa wpływają na kontekst innych wyrażeń w zdaniu. Część mowy, do której należy dane słowo może zostać zmieniona ze względu na kontekst. Świetnym anglojęzycznym przykładem (choć prawdopodobnie nie spotkamy się z takim zapytaniem w wyszukiwarce) jest zdanie:
I like how you like that he likes that.
gdzie słowo ”like” za każdym razem występuje w tej samej postaci, jednak jako inna część mowy ze względu na kontekst. W ten sposób BERT jest w stanie wyłapać niuanse, które były pomijane przez wcześniejsze modele.
4.3. Wykorzystanie architektury na wzór transformera (modelu tłumaczeniowego AI)
Większość zadań w NLU opartych jest na przewidywaniach prawdopodobieństwa. Jakie jest prawdopodobieństwo, że to zdanie odnosi się do następnego? Albo jakie jest prawdopodobieństwo, że to słowo jest częścią tego zdania? Architektura BERTa i jego modelowanie języka są częściowo zaprojektowane w celu identyfikacji i określania właściwego znaczenia niejednoznacznych słów, które zmieniają cały kontekst zdania.
„Transformery” będące modelami tłumaczeniowymi AI utrwalają słowa w kontekście, by nie mogły być niejednoznaczne. To ujednolicenie opiera się na artykule opracowanym przez Vaswaniego w 2017 z Google Brain, „Attention is all you need” (https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf). Został on publikowany rok przed artykułem badawczym dot. BERTa.
Na wzór transformerów tłumaczeniowych każde zdanie jest rozłożone na czynniki pierwsze i połączone z kontekstem. Na grafice poniżej widać, jak bardzo słowo „it” (patrz pojęcie anafory i katafory) jest faktycznie rozpoznawane jako powiązane z innymi – „the” i „animal”:
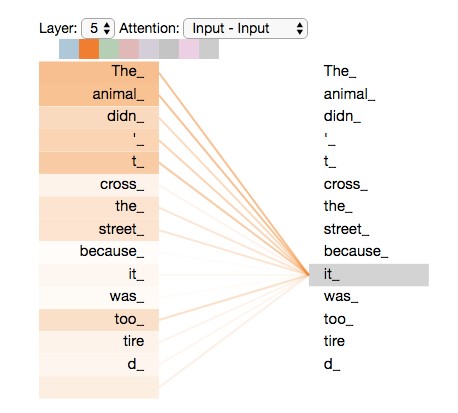
4.4. Zamaskowane modelowanie języka (szkolenie MLM, Masked Language Modelling)
Technika ta jest znana również jako „The Cloze Procedure” (https://psycnet.apa.org/record/1955-00850-001) i jest wykorzystywana już od jakiegoś czasu, jeszcze przed powstaniem BERTa. Architektura nowego modelu algorytmicznego analizuje losowo zdania z losowo zamaskowanymi słowami i stara się poprawnie przewidzieć, czym właściwie jest „ukryte” słowo. Działanie takie ma na celu, by uniknąć sytuacji, kiedy to algorytm wejdzie w nieskończoną pętlę nauki języka naturalnego, która zupełnie wypaczyłaby znaczenie analizowanego słowa.
4.5. Uwarunkowania tekstowe (przewidywanie następnego zdania)
Jednym z największych udoskonaleń BERTa jest to, że powinien on być w stanie przewidzieć to, co chcesz powiedzieć w następnej kolejności. Lub jak to określono w zeszłym roku w New York Timesie (https://www.nytimes.com/2018/11/18/technology/artificial-intelligence-language.html), „W końcu maszyna, która może dokończyć twoje zdanie.”. Posiadając dwa zdania znajdujące się obok siebie, BERT będzie w stanie przewidzieć, czy drugie zdanie pasuje kontekstowo do tego pierwszego.
W oryginalnym modelu BERTa funkcja ta została uznana za niewiarygodną, w związku z tym opracowane zostały inne open-source’owe rozwiązania, które lepiej rozwiązują ten problem. Przykładem może tu być model ALBERT od Google’a.
Jak podaje Wikipedia (https://en.wikipedia.org/wiki/Textual_entailment), analizowane pary zdań mogą mieć 3 relacje (neutralne / pozytywne / negatywne):

Do takich też wniosków może dochodzić AI przy analizowaniu poszczególnych zdań – kolejne zdanie może być dla pierwszego pasujące, niepasujące lub neutralne.
5. Google ALBERT
Google ALBERT miał swoją premierę we wrześniu 2019, stanowi połączenie sił pomiędzy Google AI i grupą badawczą Toyoty. ALBERT uznawany jest za naturalnego potomka BERTa, ponieważ osiąga najnowocześniejsze wyniki w zadaniach polegających na badaniu NLP, jednak jest w stanie to osiągnąć w znacznie bardziej wydajny i mniej kosztowny obliczeniowo sposób. Model ten ma 18 razy mniej parametrów niż BERT-Large. Jedną z głównych innowacji odróżniających go od swojego poprzednika to także poprawka w przewidywaniu kolejnego zdania.
6. Co BERT oznacza dla SEO?
Wśród seowców BERT może być odbierany jako zmiana algorytmiczna, jednak w rzeczywistości jest bardziej „aplikacją” wielowarstwowego systemu, który rozumie wieloznaczności i jest w stanie lepiej poznać odniesienia do konkretnych tematów w języku naturalnym. Robi to w sposób ciągły i stale się udoskonala dzięki możliwości uczenia się.
Głównym celem BERTa jest poprawa rozumienia języka ludzi przez maszyny. W perspektywie wyszukiwarek mowa o pisemnych i ustnych zapytaniach użytkowników, a także o treściach, które są zbierane i indeksowane przez Google. BERT rozwiązuje dwuznaczności językowe, zapewnia spójność tekstu, zwraca uwagę na najmniejsze elementy zdania decydujące o strukturze i znaczeniu.
BERT nie jest zmianą algorytmiczną jak Pingwin czy Panda ponieważ nie ocenia stron internetowych ani negatywnie, ani pozytywnie. Bardziej poprawia zrozumienie języka ludzkiego dla wyszukiwarki Google. W rezultacie Google lepiej rozumie znaczenie treści na odwiedzanych stronach, a także zapytania użytkowników, gdyż bierze pod uwagę pełen kontekst wypowiedzi.
BERT doesn't assign values to pages. It's just a way for us to better understand language.
— Danny Sullivan (@dannysullivan) October 30, 2019
BERT dotyczy zdań i fraz. Dwuznaczność jest nie tyle badana na poziome jednego słowa, co na poziomie całego zdania, ponieważ dotyczy kombinacji słów o wielu znaczeniach, które powodują tę dwuznaczność.
It's more sentences and phrases.
— Danny Sullivan (@dannysullivan) October 30, 2019
Przewiduje się, że BERT wpłynie na 10% zapytań, w których zauważyć będzie można drobne szczegóły przeważające o całym wydźwięku zdania i jego kontekście. Co więcej, może to mieć wpływ na zrozumienie nawet więcej niż 15% nowych zapytań, które Google otrzymuje każdego dnia, często odnoszących się do wydarzeń dnia codziennego. W Google Search Console zauważymy prawdopodobnie zmienioną liczbę wyświetleń strony na dane zapytania – w związku ze zwiększoną precyzją i dopasowaniem wyników wyszukiwania.
Tak zautomatyzowane działanie z pewnością wpłynie również na pracę wymienionego wcześniej zespołu Google Pygmalion, który przyłożył się do wyszukiwania głosowego, Asystenta Google, featured snippets.
6.1. Pierwszy przykład zmian w wyszukiwarce
Poniżej zamieszczamy dodatkowy przykład, który obrazuje, jak opisywane tu zagadnienia mają bezpośredni wpływ na wyniki wyszukiwania w Google. Przykład pokazuje wagę różnych części mowy i rolę ujednoznaczenia pojedynczych sów. Chociaż słowo jest małe („to”, pl: „do”), to zmienia całkowicie znaczenie zapytania, gdy jest ono uwzględniane w pełnym kontekście.
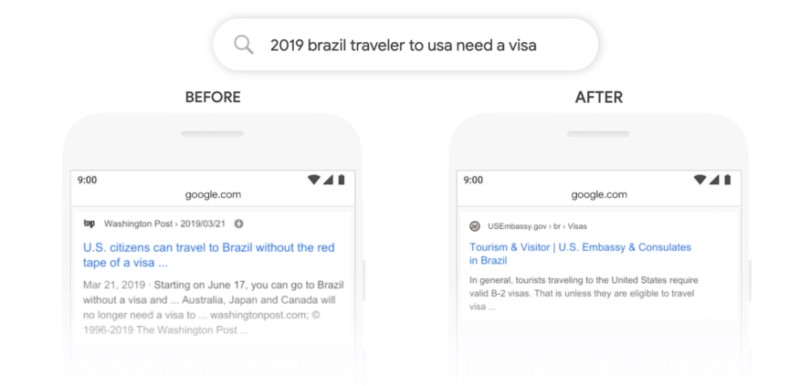
źródło: https://blog.google/products/search/search-language-understanding-bert
Fraza „2019 brazil traveler to usa need a visa” przed wprowadzeniem BERTa nie uwzględniała tzw. „stopwordsów”, pokazywały się zupełnie inne wyniki wyszukiwania niż po jego wdrożeniu. Obecne wyniki są znacznie bardziej odpowiadające intencji użytkownika.
6.2. Drugi przykład zmian w wyszukiwarce
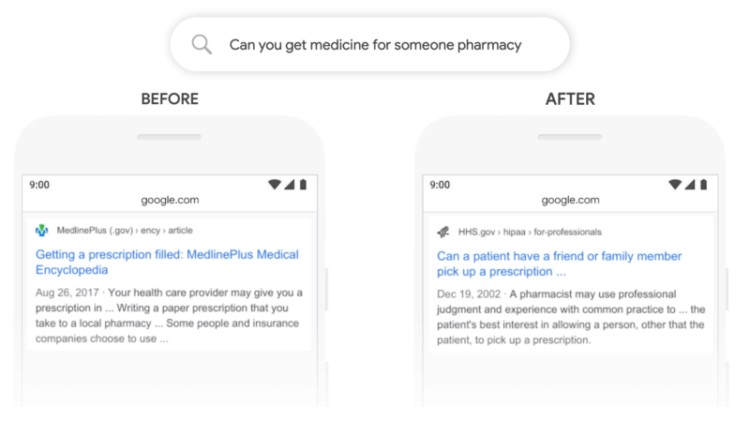
Podobnie w drugim przykładzie zaprezentowanym wprost przez Google, gdzie pod uwagę wzięta została fraza „Can you get medicine for someone pharmacy”, gdzie liczy się głównie kontekst:
6.3. Trzeci przykład zmian w wyszukiwarce
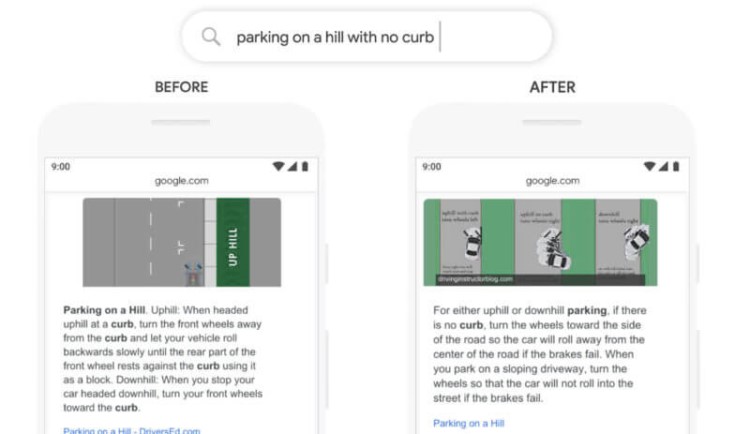
Trzeci przykład porusza temat już, o którym już wspominaliśmy niejednokrotnie w tym tekście – featured snippets. Przykładowa fraza „parking on a hill with no curb”. Wcześniej użytkownik dostawał podpowiedzi zupełnie odwrotne do swoich oczekiwań: wyszukiwarka nie brała pod uwagę słowa „no”. Obecnie internauta nie będzie zawiedziony, otrzyma od razu to, czego poszukiwał – informacji o parkowaniu na wzniesieniu bez krawężnika.
7. BERT a międzynarodowe SEO
Jednym z głównych skutków BERTa może być wpływ na międzynarodowe SEO ze względu na to, że jego odkrycia w jednym języku mogą posiadać wartość możliwą do przeniesienia na inne języki oraz domeny. Omawiany model jest o tyle nieszablonowy, że ma pewne wielojęzyczne właściwości, które w pewnym sensie wywodzą się tylko z jednego języka, a później rozszerzyły się do 104 języków w postaci M-BERTa (Multilingual BERT).
W artykule napisanym przez Piresa, Schingera i Garratte’a (https://arxiv.org/abs/1906.01502) testowano międzyjęzykowe możliwości modelu Multilingual BERT i odkryto, że „jest zadziwiająco dobry w bezobsługowym przenoszeniu wzorców międzyjęzykowych”. Jest to analogiczne do sytuacji, kiedy zrozumiałbyś język, którego wcześniej nie słyszałeś.
8. Pytania i odpowiedzi w Google
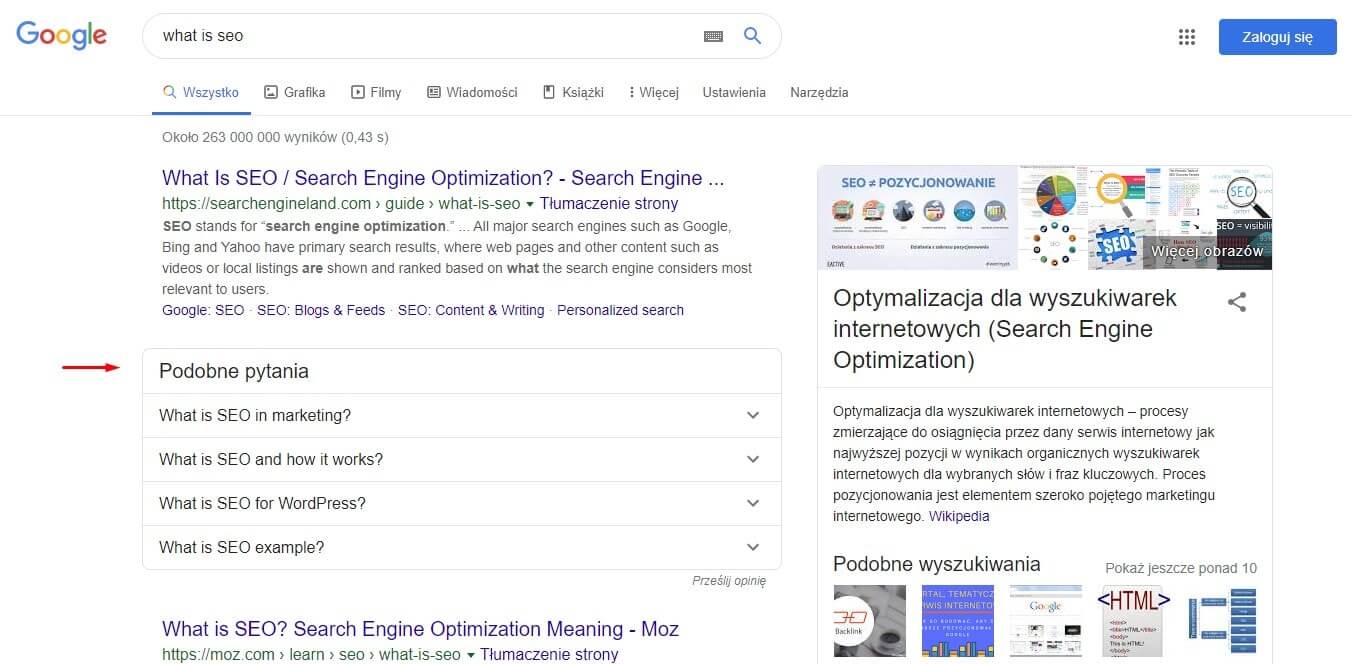
Pytania i odpowiedzi, które otrzymujemy bezpośrednio w SERPach bez konieczności wchodzenia na strony będą prawdopodobnie również bardziej rozwinięte i precyzyjne, dzięki czemu w teorii może zmniejszyć się może liczba kliknięć uzyskiwanych przez witryny internetowe. W podobny sposób, w jaki MSMARCO (http://www.msmarco.org/) jest wykorzystywany do doskonalenia się dzięki zestawom pytań i odpowiedzi użytkowników Binga, podobnie Google będzie dostarczało BERTowi zbiory danych do przyspieszenia postępów w NLU. Dzięki temu zobaczymy również prawdopodobnie zmiany, bardziej szczegółowe dopasowania w sekcji „People Also Ask” (Podobne pytania).
9. Czy strona może zostać zoptymalizowana pod BERTa?
Prawdopodobnie nie. Wewnętrzne funkcjonowanie BERTa jest złożone i wielowarstwowe. Od momentu powstania, stworzono nawet dziedzinę badań poświęconą temu modelowi, „Bertologię” (Bertology); założoną przez Hugging Face (https://huggingface.co/). Jest wysoce nieprawdopodobne, by jakikolwiek badacz wyszukiwarek mógł obecnie bezpośrednio wyjaśnić powody, dla których BERT podejmowałby decyzje dotyczące rankingu. Ze względu na zdolność ciągłej nauki uważany jest za niewytłumaczalną formę sztucznej inteligencji.
Streszczenie
- W internetowej społeczności seowców w ostatnim czasie pojawiło się sporo gifów i memów nawiązujących do postaci Berta (a czasem i Erniego) z Ulicy Sezamkowej.
- Google opisuje BERTa jako największą zmianę w systemie wyszukiwania od czasu wprowadzenia prawie pięć lat temu RankBraina, a nawet jedną z największych zmian algorytmicznych w historii wyszukiwania. Informacja o „przybyciu” BERTa i jego zbliżającym się wpływie wywołała niemałe poruszenie w społeczności SEO.
- BERT jest przełomowym technicznie modelem służącym do przetwarzania języka naturalnego, który podbija świat odkąd został wydany w postaci pracy naukowej napisanej przez Jacoba Devlina i współtwórców w 2018 r.
- Biorąc pod uwagę wszystko, co do tej pory opisaliśmy, postaramy się odpowiedzieć na pytanie dotyczące wpływu BERTa na wyszukiwarki internetowe (i in.) i ich rozumienie języka ludzkiego.
- Google ALBERT miał swoją premierę we wrześniu 2019, stanowi połączenie sił pomiędzy Google AI i grupą badawczą Toyoty. ALBERT uznawany jest za naturalnego potomka BERTa, ponieważ osiąga najnowocześniejsze wyniki w zadaniach polegających na badaniu NLP, jednak jest w stanie to osiągnąć w znacznie bardziej wydajny i mniej kosztowny obliczeniowo sposób.
- Wśród seowców BERT może być odbierany jako zmiana algorytmiczna, jednak w rzeczywistości jest bardziej „aplikacją” wielowarstwowego systemu, który rozumie wieloznaczności i jest w stanie lepiej poznać odniesienia do konkretnych tematów w języku naturalnym.
- Jednym z głównych skutków BERTa może być wpływ na międzynarodowe SEO ze względu na to, że jego odkrycia w jednym języku mogą posiadać wartość możliwą do przeniesienia na inne języki oraz domeny.
Podsumowanie
Uważa się, że BERT nie zawsze sam wie, dlaczego podejmuje decyzje. Jak więc seowcy mieliby próbować optymalizować pod niego strony? Warto jednak pamiętać o tym, że został on zaprojektowany po to, by rozumieć język naturalny, dlatego też warto w obrębie witryn dążyć do tego celu – rezygnować z wszelkich sztuczności, niskiej jakości tekstów lub tych generowanych automatycznie (sic!). Teksty powinny być przekonujące, angażujące, informacyjne i dobrze ustrukturyzowane. Tworzone dla ludzi, nie dla maszyn.
Wyszukiwarki wciąż mają przed sobą długa drogę udoskonalenia, a BERT jest jedynie jej częścią.





