
10 kroków do zwiększenia crawlowania i indeksowania witryny
Odkryj 10 kroków, które skutecznie zwiększą crawlowanie i indeksowanie witryny. Poznaj strategie, które poprawią widoczność strony w wynikach wyszukiwania. Dowiedz się, jak zoptymalizować witrynę, by przyciągnąć do niej więcej organicznego ruchu.
27.06.2023
Internet jest dynamicznie rozwijającą się przestrzenią, w której wciąż przybywa stron internetowych. Dla każdej wyszukiwarki taki ogrom danych do zebrania, przeanalizowania oraz zaindeksowania jest olbrzymim wyzwaniem. Już teraz można powiedzieć, że liczba adresów URL przekracza możliwości Google. Z...
Internet jest dynamicznie rozwijającą się przestrzenią, w której wciąż przybywa stron internetowych. Dla każdej wyszukiwarki taki ogrom danych do zebrania, przeanalizowania oraz zaindeksowania jest olbrzymim wyzwaniem. Już teraz można powiedzieć, że liczba adresów URL przekracza możliwości Google. Z tego względu czas na crawlowanie przez Googlebota danej strony jest ograniczony przez crawl budget. W rezultacie niektóre witryny nie są skanowane w całości za jednym razem i nie każdy adres URL zostanie zaindeksowany. Zanim strona pojawi się w organicznych wynikach wyszukiwania, musi być najpierw poddana wykryciu, skanowaniu, ocenie i dopiero wtedy trafia do indeksacji.
Coraz więcej stron, w szczególności tych dużych, jak np. sklepy motoryzacyjne, mają problem z indeksowaniem oraz crawl budżetem. To oczywiście przekłada się na widoczność strony na różnorodne frazy oraz finalnie na wzrost konwersji z wyników organicznych. Co więc należy zrobić, jeżeli zauważymy problemy z crawlowaniem i indeksacją strony? Artykuł przedstawia 10 kroków do zwiększenia crawlowania i indeksowania witryny. Ta wiedza może przydać się w celu dokonania pewnych zmian w strategii SEO, które mogą przełożyć się na wzrost konwersji.
Co to jest crawl budget i dlaczego warto o niego zadbać?
Crawl budget jest to liczba adresów URL konkretnej podstrony, jakie bot Google jest w stanie odwiedzić w trakcie jednorazowej wizyty. Jest to również częstotliwość, z jaką crawlery oraz boty wyszukiwarek mogą indeksować daną stronę. Google dzieli budżet indeksowania na 2. grupy czynników, które mają na niego wpływ. Są to:
- Limit wydajności indeksowania (Crawl capacity limit).
- Zapotrzebowanie na indeksowanie (Crawl demand).
Warto bliżej przyjrzeć się obu czynnikom, aby zrozumieć, jak działają boty Google oraz w jaki sposób dokonać modyfikacji w ramach swojej strony.
Limit wydajności indeksowania
Googlebot stara się indeksować stronę, nie obciążając przy tym serwera. Z tego względu obliczany jest limit wydajności indeksowania oraz dopasowywana jest ilość jednoczesnych połączeń do wydajności strony czy serwera. Im wolniejszy serwer lub strona, tym mniejszy limit crawlowania przydzieli nam Googlebot. Co więcej, jeżeli serwer często zwraca kod błędu 500 lub boty trafiają na liczne strony błędów 404, to ilość zapytań Googlebota również może spaść.
Google wskazuje na 3 czynniki wpływające na zwiększenie lub zmniejszenie wydajności indeksowania:
- Stan indeksowania – jeśli strona szybko reaguje na odpytywanie bota, to po pewnym czasie limit jest zwiększany. Jeżeli jednak czas reakcji jest długi oraz występują błędy serwera, o których wspomniano wyżej, to limit zostanie zmniejszony i Googlebot będzie skanował mniej.
- Limity ustawione przez właściciela witryny – każdy właściciel ma możliwość ograniczenia limitu odwiedzin strony przez boty Google. Bez wyraźnych przyczyn nie jest to wskazane, a ponowne zwiększenie limitu nie poprawia automatycznie wydajności indeksowania.
- Limity indeksowania Google – Google jest również ograniczone technologicznie i pomimo dużych zasobów informatycznych niestety musi hamować indeksowanie.
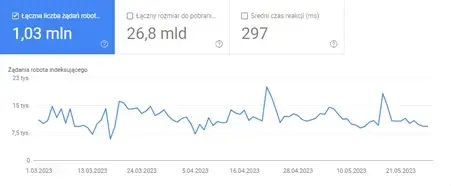
Raport Google Search Console – Statystyki indeksowania.
Chcąc więc sprawdzić, w jakim stopniu boty Google odwiedzają naszą stronę, powinniśmy odwiedzić zakładkę Statystyki indeksowania w Google Search Console.
Zapotrzebowanie na indeksowanie
Zapotrzebowanie na indeksowanie to nagradzanie za popularność strony w Internecie. Im więcej zmienia się na stronie wartościowych i aktualnych treści, tym mocniej wzrasta zainteresowanie bota Google. Istotną rolę w tym aspekcie odgrywają:
- Domniemane zasoby – bez określenia botowi, co ma skanować, a czego nie powinien, będzie on próbował przeskanować kolejno wszystkie adresy, na jakie trafi. Mogą to być strony 404, strony szablonu, adresy, które nie powinny być zaindeksowane itd. Oczywiście niepotrzebnie w ten sposób przepalamy crawl budget i należy nad tym pracować.
- Popularność – chętniej i częściej crawlowane są adresy popularne w Internecie. Nie zawsze są to te, do których prowadzi najwięcej adresów URL, często mogą być to treści newsowe, poruszające aktualną tematykę, która jest na topie.
- Aktualność – wyszukiwarka Google dąży do tego, aby wyświetlać użytkownikom tylko najbardziej aktualne wyniki. W tym wypadku nie pomaga generowanie wciąż nowych treści na blogu, muszą to być treści, które dotykają aktualnych wydarzeń, świąt, odkryć albo podobnej tematyki. Google stara się ponownie skanować adresy w celu wykrycia aktualizacji, co wpływa na ponowne zaindeksowanie bądź poprawę pozycji w organicu.
Jakie czynniki wpływają na crawl budget?
Chcąc zapanować, a z czasem zwiększyć crawl budget strony, warto zadbać o czynniki, takie jak np. crawl capacity limit i crawl demand. Tylko w ten sposób można poprawić stan zindeksowania strony, a w końcowym efekcie uda się zwiększyć widoczność serwisu.
10 kroków do zwiększenia crawlowania strony
Nie można stricte określić dokładnych działań poprawiających crawl budget, które będą idealnym rozwiązaniem dla każdej strony. Wszystko zależy od wielkości strony, niemniej jednak można wskazać 10 podstawowych działań, jakie warto wykonać, aby boty Google chętniej crawlowały i indeksowały stronę.
1. Weryfikacja serwera
Chcąc poprawić crawl budget, należy zadbać o to, aby boty nie miały, żadnych trudności z pobieraniem zawartości poszczególnych adresów. W tym wypadku warto zweryfikować stan serwera w GSC - zakładka Stan hosta.
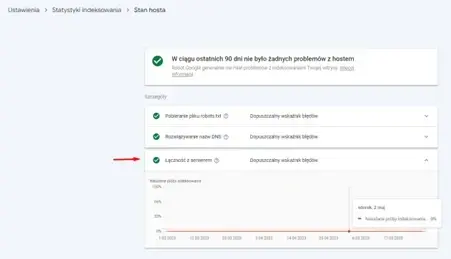
Raport Google Search Console – Stan hosta.
Jeżeli raport wskaże na liczne przerwy, to warto dokładniej przeanalizować, skąd one wynikają. Może być to chwilowy problem z serwerem, ale też permanentne przerwy. Jeżeli nie da się ich poprawić po stronie serwera, to warto zastanowić się nad przeniesieniem strony na inny hosting. Niekiedy szybszy i wydajniejszy. Niektórzy usługodawcy oferują przykładowo hostingi dedykowane pod WordPress, co w znacznym stopniu może poprawić prędkość strony oraz stabilność.
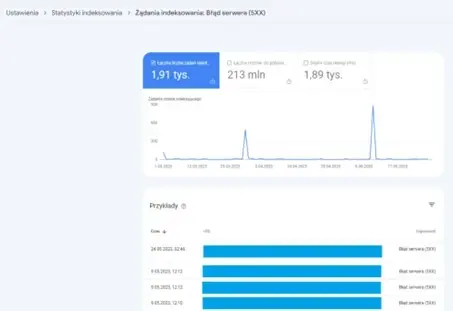
Raport Google Search Console – Żądania indeksowania: Błąd serwera (5xx).
Jeżeli konsola GSC wskazuje błędy serwera, to w zakładce Żądania indeksowania: Błąd serwera (5xx) można zweryfikować, jakie są to adresy i do jakich zasobów strony bot nie mógł się dostać, ponieważ serwer odpowiedział na jego zapytanie informacją o błędzie, czyli kodem HTTP z grupy 5xx.
2. Wyeliminowanie stron 404 i pętli przekierowań
W oszczędzaniu crawl budget należy zminimalizować ilość błędnych adresów, a także wielokrotnych przekierowań oraz pętli przekierowań. Pomóc w tym może raport: Nie znaleziono (404) w GSC bądź wykonanie crawla całego serwisu za pomocą narzędzia Screaming Frog albo Sitebulb. Dzięki crawlowi można otrzymać dokładną ilość błędnych adresów oraz ich lokalizację. W ten sposób sprawnie i skutecznie rozwiążemy problemy, jakie generują błędne adresy. Należy także pamiętać, aby usunąć adresy URL stron 404, jakie znajdują się w źródle strony.
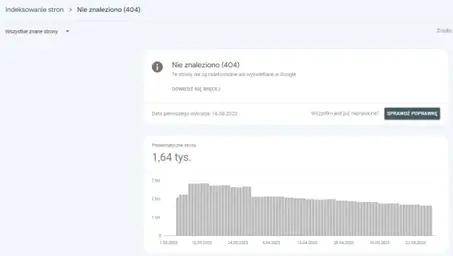
Raport Google Search Console – Nie znaleziono (404).
Podobnie należy postąpić z przekierowaniami. W tym przypadku należy zniwelować wszelkiego rodzaju łańcuchy przekierowań w ramach konkretnej domeny.
3. Blokowanie indeksacji niepożądanych stron w pliku robots.txt
Jak już wspomniano wyżej, na stronie występują adresy ważne, które chcemy, aby pojawiły się w indeksie strony, jak również i te niepożądane, na których nam nie zależy, a pochłaniają crawl budget. Do niepożądanych adresów warto zaliczyć strony szablonu, koszyka, adresy generowane na bazie zapytań z wyszukiwarki na stronie, a nawet podstrony paginacji bądź tagów – których czasami nie należy indeksować. Aby nie dopuszczać botów do takich stron, trzeba wpisać odpowiednią dyrektywę do pliku robots.txt. W ten sposób Googlebot nie będzie nawet skanował tego typu adresów.
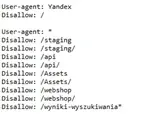
Przykład pliku robots.txt z wykluczeniem zbędnych adresów oraz bota Yandex.
Warto również usunąć nieaktualne bądź niepotrzebne reguły. Co więcej, należy również zweryfikować czy niektóre z blokowanych struktur nie są nadal crawlowane oraz, czy ich całkowite wycięcie nie wywoła błędów na stronie.
Zdarza się jednak, że niektórzy ustawiają tag noindex na stronach, których nie chcą pokazywać w indeksie. Niestety nie jest to dobra praktyka, jeśli chodzi o crawl budget, ponieważ bot i tak zaczyta nagłówek podstron noindex i choć ich nie zaindeksuje, to i tak przepali czas na próbę indeksacji.
4. Optymalizacja pliku sitemap.xml
Mapa witryny zawiera wszystkie adresy URL, które chcemy zgłosić do indeksu Google. Z tego względu powinna zawierać prawidłowe adresy URL bez przekierowań, błędów 404 czy prowadzących do podstron, których nie należy indeksować. W pliku sitemap.xml mają się znajdować tylko kanoniczne adresy URL zwracające kod 200.
Google również rekomenduje dodanie tagu
Dobrą praktyką jest podział dużych plików sitemap.xml na drobniejsze, szczególnie jak mamy do czynienia z obszernymi serwisami. Mniejsze pliki map po 20 000 adresów każdy, będą wygodniejsze do odczytu przez boty Google. Co więcej, plik sitemap można podzielić na kategorie i typy podstron. W ten sposób będzie miało się pełną kontrolę nad tym, co należy indeksować.
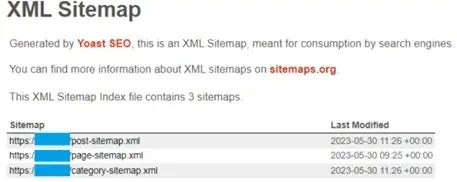
Przykład podziału mapy na mniejsze w programie Yoast SEO.
Dzięki prawidłowo zoptymalizowanemu plikowi sitemap.xml nie będziemy kierować botów do niechcianych adresów URL. A co za tym idzie? Nie będziemy marnować crawl budget. Co więcej, podział mapy na mniejszą ułatwi odczytanie jej botom i przyspieszy skanowanie znajdujących się w nich adresów.
5. Weryfikacja linkowania wewnętrznego
Linkowanie wewnętrzne jest jednym z najważniejszych aspektów, mających na celu poprawę indeksacji. Ogólna zasada jest bardzo prosta. Im głębiej zaszyty adres w strukturze strony, tym trudniej jest go zaindeksować. Wynika to z faktu, iż boty Google mają problem z dotarciem do głęboko zagnieżdżonych podstron, przemieszczając się po ubogim linkowaniu wewnętrznym. Z tego względu należy „poprowadzić” boty od zaindeksowanych już adresów, do tych najbardziej odległych. I tu natrafiamy na pojęcie struktury informacji, czyli kierowanie się zasadą, że to, co jest najważniejsze biznesowo na stronie, powinno być podlinkowane sitewide (czyli widoczne na każdej stronie) oraz na stronie głównej. Zarówno menu główne, jak i strona główna traktowane są przez boty Google, jako najważniejsze elementy.
Oczywiście w dalszych krokach, należy rozbudować linkowanie wewnętrzne, zamieszczając linki w opisach kategorii, tworząc sidebary z odesłaniami do najpopularniejszych treści na blogu czy w aktualnościach, a nawet budując zestawienia najpopularniejszych części asortymentu. W tego typu działaniach chodzi o to, aby skracać ścieżkę do podstron, które są najgłębiej.
Przykład:
Indeksowana będzie podstrona typu:
https://www.strona.pl/czesci-samochodowe/audi/a4-b8-avant-8k5/2-0-tdi-p25508/tarcze-hamulcowe
Bot Google musi przebyć drogę 5. kategorii, aby zaindeksować tę właściwą. Jest to bardzo długa droga i w wielu wypadkach, przy dużej liczbie takich kategorii bot nie zdoła wszystkich sprawnie zaindeksować, a nawet przeskanować.
W takim wypadku warto wyciągnąć najpopularniejsze adresy URL np. części samochodowe określonych wersji silnika danej marki i umieścić ich adresy URL na kategorii konkretnej marki, w tym wypadku AUDI.
Czyli należy podlinkować adres: https://www.strona.pl/czesci-samochodowe/audi/a4-b8-avant-8k5/2-0-tdi-p25508/tarcze-hamulcowe na stronie: https://www.strona.pl/czesci-samochodowe/audi/.
Podobne przykłady:
- Analogiczne działania można prowadzić na innych typach stron. Będąc np. na karcie produktowej części do konkretnego modelu samochodu, warto linkować z niej do innych modeli, do których również będzie pasować ta część.
- Z karty produktu można również linkować do jego producenta, a z karty producenta zamieścić linki do wszystkich produktów, jakie oferuje.
- Dobrym pomysłem na indeksowanie wpisów na blogu jest wyciągnięcie 4 najnowszych publikacji do strony głównej.
- Warto również tworzyć mapy HTML adresów. Są to strony zawierające zestawienia adresów, na których bardzo nam zależy. Mogą to być zestawienia cenionych marek, popularnych modułów czy producentów części itp.
Jak więc można zauważyć, pomysłów na rozbudowę linkowania wewnętrznego jest wiele, a każdy z nich przybliża nas do zwiększenia poziomu zindeksowanych stron.
Warto pamiętać, aby ręcznie zamieszczane linki prowadziły do kategorii, których adresacji nie będziemy często zmieniać np.: główne kategorie zamiast do kart produktowych, które mogą po pewnym czasie znikać. W ten sposób można uniknąć linkowania wewnętrznego, które po czasie zacznie prowadzić do stron 404.
6. Analiza filtrowania oraz mechanizmu jego działania
Dobrze zoptymalizowane filtrowanie może pomóc w budowaniu widoczności na frazy z długiego ogona. Niemniej jednak generowanie indeksowalnych filtrów, które są dowolnie ze sobą kombinowane, może szybko wyczerpać crawl budget. Co więcej, niekontrolowane indeksowanie filtrów będzie tworzyć zupełnie niepotrzebne zestawienia, które nie przyniosą żadnych korzyści SEO.
Należy zniwelować tego typu sytuacje, a indeksowalne filtry zminimalizować tylko do tych, które tworzą zestawienia wartościowych fraz, generujących wyszukiwania. Niemniej jednak każda strona jest inna i wymaga indywidualnej analizy mechanizmu filtrowania.
7. Wydajność i szybkość wczytywania stron
Jak już zostało wspomniane, skanowanie Goolgebota podlega pewnym ograniczeniom, które są związane z czasem oraz dostępnością. Z tego względu, jeżeli serwer szybko odpowiada na żądania, tym większa szansa, że bot zindeksuje więcej adresów URL. Tu warto pamiętać, że boty Google preferują indeksowanie treści wysokiej jakości, warto więc wiedzieć, że przyspieszenie stron o niskiej jakości może zniechęcić bota Google do indeksacji pozostałej części strony.
Raport Google Search Console – Statystyki indeksowania.
Tu warto zwrócić uwagę nie tylko na wydajność serwera, ale również na czas wczytywania oraz uruchamiania zamieszczonych zasobów, takich jak zdjęcia czy też skrypty. Warto zweryfikować nieużywane wtyczki i je odinstalować. Należy także wykryć te z nich, które odpowiadają za to samo – w takiej sytuacji lepiej wprowadzić jedną wtyczkę zamiast 3. Warto również pamiętać o dużych zasobach, które powoli się wczytują, takie jak slidery, filmy wideo itp. Im dłużej się strona wczytuje, tym mniejsze prawdopodobieństwo, że zostanie zindeksowana.
8. Weryfikacja stron posiadających tag noindex
Jak można domyślać się, tag noindex informuje boty Google, aby nie indeksowały konkretnych adresów. Nie jest to jednak zapora przed wizytą bota na takich adresach. Mając do dyspozycji strony z tagiem noindex, można „przepalać” crawl budget.
Przykład:
Wiele stron posiada blogi, na których zamieszczone są tagi, które dodawane są w sposób dobrowolny, często bez większego uporządkowania. Tłumaczone to jest przez właścicieli stron wygodą użytkowania. Tego typu tagi często nie są jednak indeksowane, aby nie posiadać w indeksie bezwartościowych adresów. Niestety przy dużej liczbie wpisów i przypadającej na 1 wpis około 2 lub 3 tagi, generuje się całkiem sporą ilość adresów URL, które boty odwiedzają i przepalają crawl budget.
Zapisz się na newsletter i bądź na bieżąco z naszymi artykułami z bloga. Nie przegap najciekawszych naszych wpisów.
Administratorem udostępnionych przez Ciebie danych osobowych jest Ideo Force Sp. z o.o. Podanie danych osobowych jest dobrowolne, jednak ich niepodanie uniemożliwi świadczenie usług na Twoją rzecz. Dowiedz się więcej o zasadach przetwarzania Twoich danych osobowych oraz przysługujących Ci uprawnieniach w Polityce prywatności.
Rozwiązaniem takiej sytuacji może być zupełne zrezygnowanie z tagów na poczet kilku kategorii, ewentualnie konsolidacja wszystkich tagów do kilkunastu wartościowych.
9. Niwelowanie duplikowanych treści
Na każdej stronie warto przeanalizować duplikaty adresów generowanych np. przez: paginacje czy infinity scroll, filtry, podstrony ze zduplikowaną treścią, wersje językowe z treścią w tym samym języku itd. Google wskazuje, że strony, które są duplikatami oryginalnego adresu, powinny być oznaczone adresem kanonicznym, czyli wskazywać na oryginalny adres URL. Jeżeli nie można tego określić, to Google może samo wybrać stronę kanoniczną, niekiedy nawet inną niż ta, która została wybrana w kodzie.
Tu warto również zastanowić się, czy nie powinno się ukryć w źródle strony adresy, które generują duplikaty, tak aby bot Google, nie mógł na nie trafić i przeskanować. Tu dobrym przykładem są filtry. Jeżeli nie zaszyje się adresów URL filtrów w źródle strony, to można uniknąć skanowania oraz prób indeksacji, co z kolei zaoszczędzi crawl budget.
10. Popraw indeksację dbając o jakość treści
Uważa się, że wprowadzając drobne zmiany w już istniejącej treści, takie jak aktualizacja daty publikacji, albo dodanie niewielkiego akapitu treści, poprawi indeksację. To niestety w wielu wypadkach nie wystarczy. Każda treść na stronie oceniana jest w kontekście jakości bez względu na datę jej utworzenia.
Co więcej, generowanie dużej ilości treści, ale niskiej jakości, która nie przyniesie żadnej korzyści użytkownikowi, a jest generowana choćby ze względu na chęć pozyskanie linku, albo dla samej frazy, również może nie być indeksowana.
Indeksację może poprawić tworzenie treści o wysokiej jakości, takiej, która będzie odpowiedzią na nurtujące pytanie internautów, bądź też będzie dotyczyć aktualnych lub zbliżających się wydarzeń. Warto także zadbać, aby tworzone treści były generowane przez specjalistów w danej dziedzinie, którzy mają doświadczenie i profesjonalną wiedzę.
Streszczenie
-
Internet to rozwijająca się przestrzeń z nieustannie powstającymi stronami internetowymi, co stanowi ogromne wyzwanie dla wyszukiwarek, które muszą zbierać, analizować i indeksować ogromne ilości danych.
-
Problem ograniczonego crawl budget Googlebota powoduje, że nie wszystkie strony są skanowane i zaindeksowane, co ma wpływ na ich widoczność w wynikach wyszukiwania.
-
Crawl budget to liczba adresów URL podstrony, które bot Google może odwiedzić podczas jednej wizyty. Określa również częstotliwość, z jaką crawlery i boty wyszukiwarek mogą indeksować daną stronę.
-
Google dzieli budżet indeksowania na limit wydajności indeksowania (Crawl capacity limit) oraz zapotrzebowanie na indeksowanie (Crawl demand).
-
Google wyróżnia 3 czynniki wpływające na zwiększenie lub zmniejszenie wydajności indeksowania, czyli stan indeksowania, limit ustawiony przez właściciela witryny oraz limity indeksowania Google.
-
Zapotrzebowanie na indeksowanie stron zależy od wartościowych treści. Aby efektywnie indeksować strony, należy odpowiednio zarządzać domniemanymi zasobami, unikając zbędnego przeskanowania niepotrzebnych adresów. Popularność strony i aktualność jej treści ma kluczowe znaczenie dla częstotliwości przeglądania jej przez bota.
-
Na zwiększenie crawlowania witryny wpływa: weryfikacja serwera, wyeliminowanie stron 404 i pętli przekierowań, blokowanie indeksacji niepożądanych stron w pliku robots.txt, optymalizacja pliku sitemap.xml, weryfikacja linkowania wewnętrznego, analiza filtrowania oraz mechanizmu jego działania, wydajność i szybkość wczytywania stron, weryfikacja stron posiadających tag noindex, niwelowanie zduplikowanych treści czy jakość treści.
Podsumowanie
Praca nad crawl budget oraz indeksacją to niekiedy mozolna walka. Im strona jest bardziej rozbudowana, tym więcej przeszkód przed nami. Inaczej wygląda sytuacja ze stroną mającą 100 adresów URL, a zupełnie inaczej w wypadku sklepów posiadających setki tysięcy adresów URL. Można więc stwierdzić, że „Im dalej w las, tym więcej drzew”. Niekiedy pojawiają się również sytuacje, kiedy to wszystko wygląda na pozór dobrze, ale bot Google, z jakiegoś powodu nie chce indeksować podstron. W takich sytuacjach, kiedy „uniwersalne” praktyki zawodzą, zaczyna się eksploracja alternatywnych rozwiązań. Warto pamiętać, że racjonalne rozdzielenie crawl budżetu poprzez prezentację botom tych treści, które są ważne i wartościowe, przełoży się na wzrost indeksacji, a im więcej adresów URL w wynikach organicznych, tym większa widoczność, a w efekcie przyrost konwersji.


