

Boty Google – rodzaje i funkcje
Według Google istnieje co najmniej 18 różnych rodzajów botów. Zdobycie informacji o nich, jest dla specjalistów SEO, jak analiza graczy drużyny przeciwnej. Wiedząc, jakimi zawodnikami dysponuje przeciwnik, łatwiej ułożyć strategię, wchodząc do gry.
23.02.2024
Uczestnicząc w różnego rodzaju kursach z zakresu pozycjonowania, można dowiedzieć się wiele o analizie słów kluczowych, architekturze treści na stronie, metodach pozyskiwania backlinków, czy optymalizacji technicznej. Jest to zrozumiałe, ponieważ opanowanie tych zagadnień pozwala na rozpoczęcie działań z obszaru SEO. Mając już fundamentalną wiedzę, warto wrócić do teorii i spojrzeć na cały proces od strony wyszukiwarki. Uwagę warto skierować zwłaszcza w stronę robotów indeksujących.
Roboty indeksujące – czym są i jakie są ich zadania?
Sama nazwa „roboty indeksujące” wprowadza swoistą niepewność. Czy w siedzibie Google funkcjonują elektroniczne maszyny, które wyglądem przypominają bohaterów z filmów fantasy, a ich zadaniem jest przeglądanie ogromnej liczby stron? Nie, jednak mimo że Google stara się kreować ich wizerunek w ten sposób, to w rzeczywistości są to specjalne programy komputerowe.

Źródło: Googlebot https://developers.google.com/search?hl=pl.
Roboty indeksujące są nazywane również botami, pająkami, czy crawlerami. Jak możemy przeczytać w dokumentacji, istnieje 18 najważniejszych rodzajów botów. Każdy z nich jest odpowiedzialny za skanowanie stron internetowych, jednak specyfika zadań, które wykonują poszczególne roboty, pozwala je różnicować.
Podział robotów Google
Oficjalnie wyróżnia się 18 różnych rodzajów robotów. Roboty mają przypisane specjalne tokeny, które reprezentują je podczas ustalania reguł indeksowania w pliku robots.txt. Przy ich ustalaniu należy być szczególnie ostrożnym, ponieważ niektóre roboty posiadają te same tokeny, co oznacza, że ustalone reguły mogą dotyczyć kilku robotów. W ten sposób możemy nieumyślnie zablokować przed indeksowaniem więcej robotów, niż pierwotnie zamierzaliśmy.
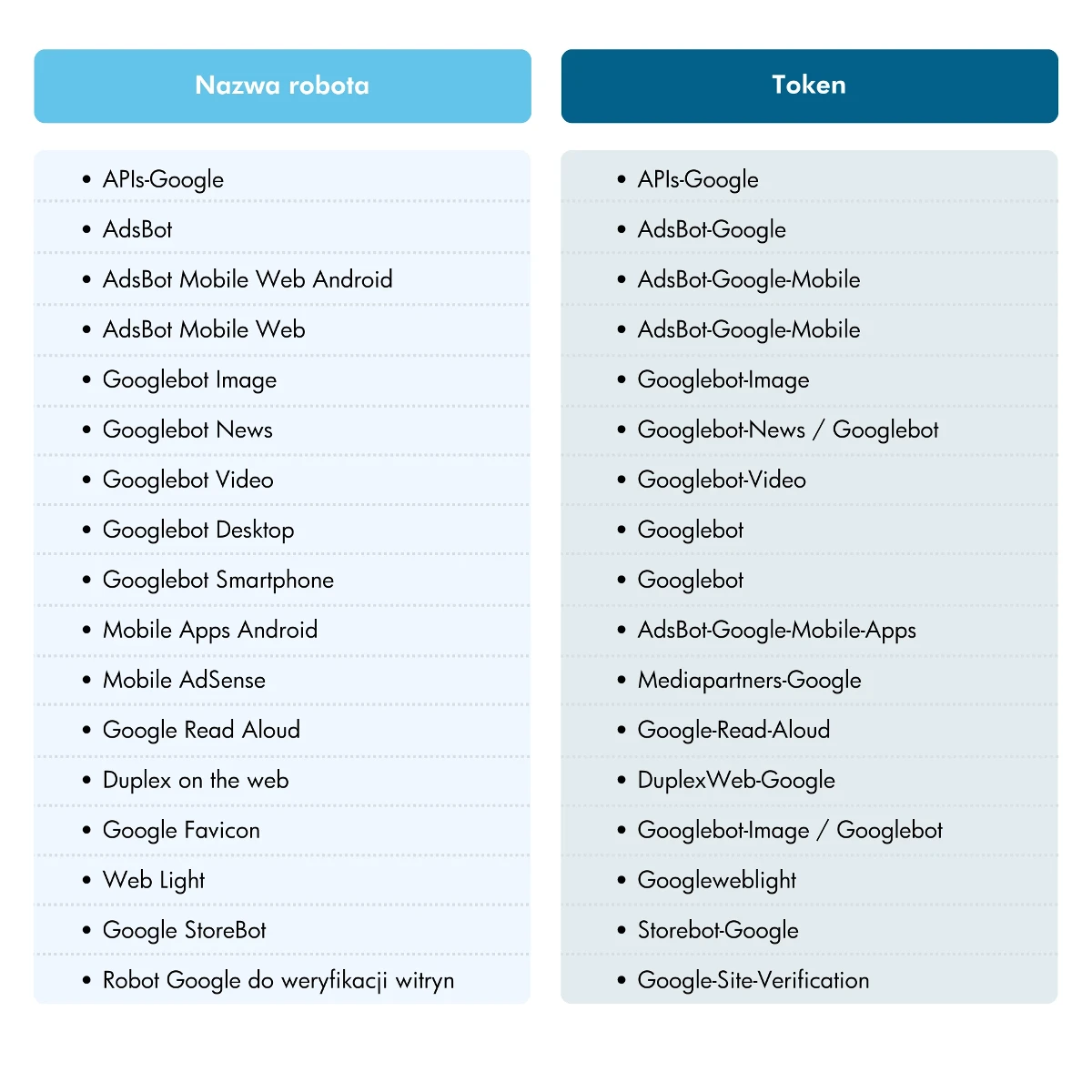
Samo Google zaznacza, że są to tylko najpopularniejsze rodzaje robotów, które docierają na nasze strony internetowe: „Ta tabela zawiera informacje na temat najpopularniejszych robotów Google, które możesz zobaczyć w dziennikach strony odsyłającej oraz sposobu ich określania w pliku robots.txt, metatagach robots i dyrektywach HTTP.” [ Źródło:https://developers.google.com/search/docs/advanced/crawling/overview-google-crawlers?hl=pl ].
API-s Google
Pierwszy bot na liście to APIs-Google, wykorzystywany w interfejsach Google API np. Google Analytics Data API, AdSense Management API (pełna lista dostępna tutaj: https://developers.google.com/apis-explorer) do dostarczania komunikatów z powiadomieniami push. Rozwiązanie to ogranicza liczbę zapytań wysyłanych do serwerów Google o ewentualne zmiany zasobów.
Po zweryfikowaniu własności domeny, powiadomienia push są wysyłane cyklicznie w konkretnych odstępach czasowych. Jako że robot dostarcza powiadomienia push, wykorzystując protokół HTTPS, właściciel domeny powinien zadbać o ważny, pochodzący z zaufanego źródła certyfikat SSL. Sama aplikacja powinna być tak skonstruowana, aby była w stanie odpowiedzieć na powiadomienie w ciągu kilku sekund.
Jeżeli nie chcemy otrzymywać powiadomień, możemy zablokować je w pliku robots.txt.
AdSense
Robot indeksujący AdSense został stworzony po to, by przemierzać witryny, określać ich zawartość oraz wyłuskiwać te elementy, które są najistotniejsze do wyświetlania reklam. Odwiedza wszystkie strony, które nie są zablokowane przed indeksowaniem oraz, które zawierają tagi reklam. Robot AdSense aktualizuje swój raport o witrynie co tydzień i nie możemy w żaden sposób wpłynąć na przyspieszenie tego procesu. Wprowadzając zmiany na stronie, musimy zatem uzbroić się w cierpliwość, ponieważ mogą pojawić się w indeksie po upłynięciu nawet 2 tygodni.
Nie należy mylić go z Googlebotem – są to 2 oddzielne twory, które nigdy nie wchodzą sobie w drogę. Jeśli jeden z nich przebywa aktualnie na stronie, drugi będzie cierpliwie czekał na swoją kolej, tak aby nie obciążać przepustowości łączy.
Jeśli chodzi o blokowanie robota AdSense w pliku robots.txt należy zwrócić uwagę na pewien aspekt, a mianowicie używając blokady User-agent:*, robot indeksujący AdSense wciąż będzie mógł indeksować podstrony w obrębie witryny. Aby tego uniknąć, należy umieścić w pliku robots.txt wiersz User-agent: Mediapartners-Google.
Robot indeksujący AdSense posiada swojego odpowiednika na wersje mobilne – Mobile AdSense.
AdsBot
Adsbot jest to specjalny robot, który ocenia reklamę, biorąc pod uwagę takie czynniki, jak jakość strony docelowej, trafność reklamy oraz przewidywany współczynnik klikalności CTR).
W zależności od rodzaju obsługiwanego urządzenia Adsboty możemy podzielić na:
- AdsBot Mobile Web Android - robot sprawdzający jakość reklam na stronie internetowej, na urządzeniach mobilnych z systemem Android.
- AdsBot Mobile Web - robot sprawdzający jakość reklam na stronie internetowej na iPhone’ach oraz komputerach.
- Mobile Apps Android - robot sprawdzający jakość reklam na stronie aplikacji na Androida.
Googlebot
Najważniejszy z punktu widzenia SEO robot indeksujący, który właściwie występuje w dwóch postaciach, jako robot indeksujący strony na smartfony oraz robot komputerowy. Zadaniem Googlebota jest „podszycie się” pod użytkownika na urządzeniu mobilnym lub stacjonarnym, a następnie zebranie odpowiedniej ilości informacji o stronie. Ostatecznie wszystkie dane zebrane przez Googlebota decydują o kształcie, w jakim prezentuje się indeks wyszukiwarki.
Maksymalna wielkość danych, jaką Googlebot może zindeksować wynosi pierwsze 15MB pliku HTML, czy innego obsługiwanego pliku tekstowego. Po przeskanowaniu takiej ilości danych Googlebot przejdzie dalej, nawet jeżeli plik jest większy i zostało jeszcze sporo danych do zindeksowania. Warto więc dbać o odpowiedni rozmiar plików.
Zapisz się na newsletter i bądź na bieżąco z naszymi artykułami z bloga. Nie przegap najciekawszych naszych wpisów.
Administratorem udostępnionych przez Ciebie danych osobowych jest Ideo Force Sp. z o.o. Podanie danych osobowych jest dobrowolne, jednak ich niepodanie uniemożliwi świadczenie usług na Twoją rzecz. Dowiedz się więcej o zasadach przetwarzania Twoich danych osobowych oraz przysługujących Ci uprawnieniach w Polityce prywatności.
Istnieją specjalne rodzaje klientów Googlebotów, zajmujące się pobieraniem zasobów wymienionych w kodzie HTML – np. obrazy, filmy, pliki CSS i JS. Są to m.in.:
- Googlebot Image
- Googlebot News
- Googlebot Video
Jako że Googlebot działa na tysiącach komputerów, w dziennikach możemy odnotować aktywność z wielu różnych urządzeń z adresem google.com, natomiast więcej o tym jak weryfikować autentyczność crawlerów, w dalszej części artykułu.
Web Light
Google Web Light to usługa umożliwiająca szybsze przeglądanie stron w mobilnej przeglądarce Google Chrome na Androidzie oraz na telefonach KaiOS. Web Light jest szczególnie przydatne dla użytkowników dysponujących wolniejszym połączeniem internetowym. Pozwala wyświetlić uproszczoną wersję strony, tak aby zminimalizować użycie transmisji mobilnych danych.
Usługa Web Light włącza się przy próbie wczytania witryny z wyników wyszukiwania po wykryciu wolniejszego łącza na urządzeniu użytkownika. Transkodowanie uruchamia się w momencie, w którym zostanie wykryte wolniejsze łącze.
Google Favicon
Robot indeksujący, który od czasu do czasu odwiedza stronę główną w celu sprawdzenia aktualności favikony. Favikona to mała ikonka pojawiająca się w wynikach wyszukiwania tuż obok nazwy strony:
Źródło: Google.
Istnieje kilka wymogów, które musi spełnić favikona, zanim będzie widoczna w SERPach. Przede wszystkim możliwe jest zdefiniowanie tylko jednej favikony dla witryny, dlatego np. definiowanie różnych favikon dla oddzielnych podstron, jest niemożliwe. Oczywiście Google musi mieć dostęp zarówno do strony głównej, jak i do favikony.
Google Duplex on the web
Funkcja Duplex on the web jest ściśle powiązana z Asystentem Google. Wchodząc na stronę, klient jest odpowiedzialny za testowanie możliwości wykorzystania funkcji asystenta na stronie. Funkcje, z których najczęściej korzystają użytkownicy, to m.in.:
- zakup biletów do kina, zamawianie jedzenia w witrynach restauracji,
- wspomagana odprawa w witrynach linii lotniczych,
- automatyczne zmienianie hasła,
- automatyczne znajdowanie rabatów.
Google Read Aloud
Choć Google umieściło go w przeglądzie robotów, tak naprawdę Google Read Aloud nie jest botem, a bardzo popularną usługą, polegającą na zamianie tekstu na stronie na mowę. Uruchamia się po wejściu do witryny, pod warunkiem że użytkownik ma włączoną funkcję TTS, a dostęp do treści nie został zablokowany. W celu oszczędności zasobów skanowanie strony odbywa się tylko na żądanie użytkownika.
Moduł pobierania kanałów
Moduł pobierania kanałów indeksuje kanały RSS lub Atom podcastów i wiadomości Google. Jego głównym celem jest dostarczanie powiadomień o zmianach w czasie rzeczywistym. Ma to zapobiegać występowaniu sytuacji, w których klient, co jakiś czas, samodzielnie odpytuje serwer kanałów w dowolnych odstępach czasu. W ten sposób WebSub zapewnia wypychane powiadomienia HTTP bez konieczności wydawania zasobów na sondowanie zmian.
Jako że moduł pobierania kanałów, nie przestrzega wytycznych z pliku robots.txt, dość trudnym zadaniem, jest zablokowanie dostępu do materiałów przed Google. W takiej sytuacji warto spróbować skonfigurować serwer witryny tak, aby zwracał kod 404 lub inny błąd dla klienta Feedfetcher-Google.
Google StoreBot
Bot ściśle związany z Google Merchant Center, sprawdza najważniejsze informacje o produkcie, takie jak cena, kod, dostępność, koszt wysyłki.
Robot do weryfikacji witryn
To ostatni robot, który znalazł się w oficjalnym zestawieniu Google. Jego zadaniem jest weryfikacja własności witryny przeprowadzana przy dodawaniu usługi w Google Search Console.
Kontrola ruchu botów w obrębie witryny
Istnieje kilka sposobów na kontrolę ruchu robotów oraz tego, co może być pobierane i indeksowane.
- Robots.txt – wielokrotnie wspominany wcześniej plik. Pozwala kontrolować to, co jest i co może być indeksowane w Twojej witrynie.
- Nofollow – to atrybut linku lub meta tag robots, który sugeruje, że nie należy podążać za linkiem. Jest to tylko wskazówka, więc można ją zignorować.
- Zmień szybkość indeksowania – to narzędzie w Google Search Console, pozwala spowolnić indeksowanie Google.
- Narzędzie do usuwania adresów URL – nazwa tego narzędzia od Google jest nieco myląca, ponieważ sposób jego działania polega na tymczasowym ukryciu treści. Google nadal będzie widzieć i indeksować te treści, ale strony, nie będą się pojawiać w wynikach wyszukiwania.
Statystyki indeksowania
W Google Search Console mamy dostęp do raportu „Statystyki indeksowania”. Można go znaleźć, klikając „Ustawienia” > „Statystyki indeksowania”. Raport zawiera wiele ciekawych informacji o tym, jak Google indeksuje witrynę. Można dowiedzieć się z niego, który Googlebot, jakie pliki zaindeksował i kiedy uzyskał do nich dostęp.
Botem, który zawsze powinien zajmować pierwsze miejsce w statystykach indeksowania naszej strony, jest Googlebot na smartfony. Wynika to z podejścia do projektowania nowoczesnych stron internetowych „mobile first”. Jeżeli większość stron w obrębie witryny jest zaprojektowana zgodnie z tą myślą, znaczna część żądań będzie pochodzić od robota mobilnego. W przeciwnym wypadku należy przeanalizować budowę strony pod kątem możliwych błędów.
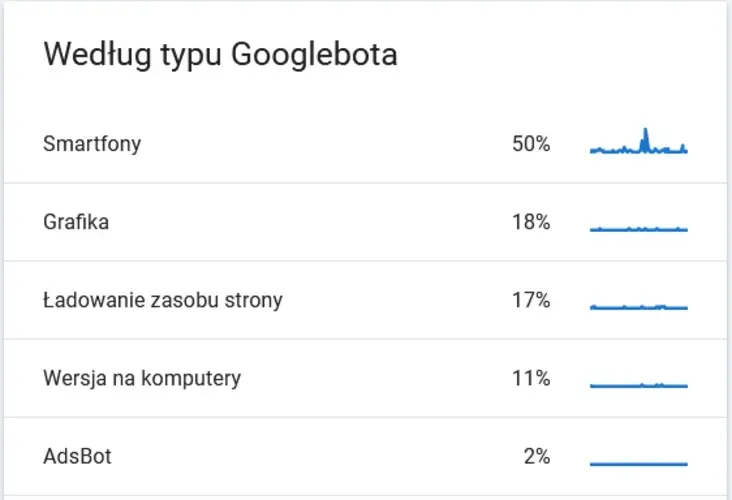
Źródło: Google Search Console.
Weryfikacja wiarygodności Googlebotów
Często pojawiającym się problemem jest podszywanie się pod boty Google, innych złośliwych botów, próbujących w ten sposób uzyskać dostęp do stron. W celu zapobiegania takim sytuacjom, Google udostępniło publiczną listę adresów IP, z których pochodzą żądania Googlebotów. Dzięki tym informacjom w prosty sposób można wychwycić każdą próbę podszywania się pod roboty Google. Wystarczy porównać adresy z listy z tymi, które pokazują się w logach serwera. Jeżeli na liście nie znaleźliśmy adresu IP, który znalazł się w logach serwera, warto zajrzeć do rozszerzonej listy adresów IP, z których Google może uzyskać dostęp do witryny.
Zmniejszanie szybkości indeksowania
Google przyzwyczaiło nas, że zawsze stara się optymalizować wszystkie swoje działania. Nie inaczej jest w przypadku procesu indeksowania stron. Celem botów jest zindeksowanie jak największej liczby stron podczas pojedynczej wizyty, bez znaczącego obciążania serwera. Z perspektywy Google działanie to jest jak najbardziej zrozumiałe. Nie oznacza to, że zawsze jest ono optymalne i nie doprowadza do rzeczywistych obciążeń. Aby nie narażać właścicieli witryn na utratę przychodów przez przeciążenie, Google umożliwia zmniejszanie liczby żądań nadsyłanych przez Googlebota. Można to zrobić w Google Search Console, przesyłając prośbę o zmniejszenie intensywności indeksowania.
Innym bardziej doraźnym sposobem, jest ustawienie strony błędu z kodem 500,503 lub 429. Googlebot napotykając strony zwracające tego typu kody, automatycznie zmniejszy szybkość indeksowania oraz liczbę wysyłanych zapytań, co pomoże odciążyć serwer. Stosowanie tej metody nie jest zalecane przez czas dłuższy niż 1-2 dni, ponieważ po tym czasie, Google prawdopodobnie usunie błędne podstrony z indeksu.
Streszczenie
- Roboty indeksujące to specjalne programy komputerowe, nazywane także botami, pająkami, czy crawlerami.
-
Wyróżnia się 18 rodzajów robotów, z których każdy ma przypisany swój token.
-
Do botów zalicza się API-s Google, AdSense, AdsBot, Googlebot, Web Light, Google Favicon, Google Duplex on the web, Google Read Aloud, Moduł pobierania kanałów, Google StoreBot, czy Robot do weryfikacji witryn.
-
Częstym problemem jest podszywanie się pod boty Google, innych złośliwych botów, próbujących w ten sposób uzyskać dostęp do stron. W celu zapobiegania takim sytuacjom, Google udostępniło publiczną listę adresów IP, z których pochodzą żądania Googlebotów.
Podsumowanie
Po lekturze artykułu słowa „Googlebot”, „robot Google”, czy „crawler” powinny być bardziej jasne, a poruszanie się w tematyce botów, nie powinno sprawiać już większych problemów. Jeżeli podczas czytania pojawiły się pytania, chętnie na nie odpowiem. Zachęcam również do lektury pozostałych artykułów z Akademii Ideo Force, w których można znaleźć szereg praktycznych wskazówek z obszaru SEO i nie tylko.
Bibliografia
- https://www.cloudskillsboost.google/focuses/3473?locale=pl&parent=catalog
- https://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers?hl=pl#weblight
- https://developers.google.com/search/docs/advanced/crawling/overview-google-crawlers?hl=pl
- https://support.google.com/google-ads/answer/6167118
- https://support.google.com/adsense/answer/99376?hl=pl&utm_source=developers.google.com&utm_medium=referral
- https://ahrefs.com/blog/googlebot/
- https://developers.google.com/search/docs/crawling-indexing/feedfetcher
- https://developers.google.com/search/docs/crawling-indexing/read-aloud-user-agent
- https://developers.google.com/search/docs/advanced/crawling/duplex-user-agent?hl=pl
- https://developers.google.com/search/docs/appearance/favicon-in-search?hl=pl#crawler
