
Crawl budget - czym jest i jak wpływa na pozycjonowanie?
Wyszukiwarka Google jest jednym z głównych narzędzi, wykorzystywanych do zdobywania informacji o produktach i usługach. By witryna mogła trafić do wyników wyszukiwania i zaistnieć w świadomości klientów, musi spełniać szereg wymagań. Jakich? Sprawdźmy.
28.04.2023
Klienci wielokrotnie korzystają ze wszelkiego rodzaju wyszukiwarek w celach zakupowych. Są to dla nich jedne z najważniejszych narzędzi do pozyskiwania wartościowych informacji. Znane wszystkim Google dysponuje obszerną bazą danych, która pozwala użytkownikom znaleźć odpowiedzi na niemal wszystkie z...
Klienci wielokrotnie korzystają ze wszelkiego rodzaju wyszukiwarek w celach zakupowych. Są to dla nich jedne z najważniejszych narzędzi do pozyskiwania wartościowych informacji. Znane wszystkim Google dysponuje obszerną bazą danych, która pozwala użytkownikom znaleźć odpowiedzi na niemal wszystkie zadawane przez nich pytania. Niemniej jednak, aby witryna mogła pojawić się w organicznych wynikach wyszukiwania na wybrane frazy kluczowe, konieczne jest jej przeskanowanie, a następnie zaindeksowanie przez tzw. Googleboty.
Roboty sieciowe regularnie przeszukują Internet w celu znajdywania wartościowych treści. Jednakże ich działanie jest ograniczone i nie są w stanie stale przebywać na tych samych witrynach, aby sprawdzać, czy pojawiły się na nich nowe treści. Termin crawl budget częściowo opisuje ograniczenia, które boty napotykają, w trakcie swojej codziennej pracy.
Spis treści:
- Wyszukiwarka Google – jak działa i zbiera informacje?
- Czym zatem jest crawl budget?
- Budżet indeksowania – przydatne narzędzia
- Streszczenie
- Podsumowanie
Wyszukiwarka Google – jak działa i zbiera informacje?
Mówiąc o budżecie crawlowania, trudno nie poruszyć tematu związanego z pozyskiwaniem, indeksowaniem oraz porządkowaniem informacji przez wyszukiwarkę Google. W końcu są to elementy fundamentalne, które mają przełożenie na pozycję witryny w organicznych, czyli bezpłatnych wynikach wyszukiwania.
Skanowanie
Zacznijmy od kroku pierwszego, czyli skanowania. Budżet crawlowania opiera się w tym miejscu na robotach sieciowych, które przeszukują zasoby Internetu, w celu wykrycia wszelkiego rodzaju odnośników, plików oraz danych. Tym samym dokonują one analizy treści, która znajduje się na wybranej stronie internetowej. Zazwyczaj crawlery zaczynają poruszać się po najpopularniejszych miejscach w witrynie, a następnie przechodzić dalej, do tych bardziej ukrytych zasobów. Dlatego w pierwszym etapie skanowania roboty sieciowe odwiedzają stronę internetową i skanują jej zawartości, po to, by pobrać część jej zasobów. Następnie, witryna jest poddawana renderowaniu. Innymi słowy, uruchamiany jest kod witryny oraz oceniania zostaje jej zawartość, treść, struktura i layout. Aby przeskanowanie konkretnej strony internetowej było możliwe, wyszukiwarka Google musi niejako mieć świadomość jej istnienia. Musi więc dowiedzieć się o niej m.in. z pomocą:
- linków z innych witryn znajdujących się w indeksie, za którymi może podążać,
- mapy strony z danym adresem internetowym, która została przekazana do usługi Google Search Console.
Indeksacja
Po przeskanowaniu witryny zaczyna się etap indeksacji. W trakcie tego procesu odbywa się zbieranie informacji, między innymi o treściach, frazach kluczowych, linkach wewnętrznych/zewnętrznych oraz grafikach, które znajdują się w obrębie danej strony internetowej. W ten sposób mogą być one zapisane w bazie danych wyszukiwarki, w tak zwanym indeksie. Warto tutaj zaznaczyć, że to roboty sieciowe oceniają daną stronę internetową oraz klasyfikują jej wartość na podstawie zebranych danych. Jeżeli okaże się ona niesatysfakcjonująca, nie możemy oczekiwać osiągnięcia przez daną stronę internetową wysokich pozycji w organicznych wynikach wyszukiwania.
Trzeba przy tym procesie również pamiętać o tym, że niezależnie od tego, jaką liczbę podstron posiada dana witryna, jej adresy URL indeksowane są pojedynczo. I z tym działaniem związany jest termin crawl budżetu, który opiera się na czasie, jaki roboty sieciowe mogą poświęcić na indeksowanie zasobów określonej strony internetowej. Stąd, aby adresy URL mogły zostać w większości przypadków zaindeksowane, warto zadbać w pierwszej kolejności o optymalizację pewnych elementów. Co więc należy zrobić?
- Zweryfikować poprawność działania nawigacji fasadowej, która dotyczy opcji filtrowania. Wszystko dlatego, że może ona generować wiele niepotrzebnych adresów URL, które będą miały negatywny wpływ na budżet indeksowania witryny.
- Unikać zjawiska duplicate content, które dotyczy umieszczania tych samych treści w obrębie witryny, albo poza nią. Ponieważ może to skutkować tym, że roboty sieciowe ograniczą widoczność strony internetowej.
- Usuwać miękkie błędy 404, które mogą polegać na tym, że np. serwer zwraca kod odpowiedzi 200 na nieistniejących podstronach. To nierzadko negatywnie wpływa na crawl budget, jaki jest przeznaczony na witrynę.
- Unikać tzw. thin contentu. Nie należy publikować treści, które nie mają wartości dla użytkownika, gdyż są ona źle oceniane przez roboty wyszukiwarek.
- Wyłączyć indeksowanie podstron, które mają mniejsze znaczenie w procesie pozycjonowania. Można to zrobić np. przy pomocy pliku robots.txt lub meta znaczników.
- Zadbać o postać mapy strony, która nie powinna zwracać błędów. Jeżeli zaniedbamy ten element, możemy doprowadzić do obniżenia budżetu indeksowania swojej witryny.
- Systematycznie aktualizować i publikować unikalną treść, ponieważ stanowi to zachęte dla robotów sieciowych do częstszego wchodzenia na daną witrynę.
Na etapie indeksowania Googleboty starają się tak naprawdę zrozumieć tematykę pobieranej strony internetowej, a także starają się określić, czy dana zawartość jest unikalna, czy może stanowi duplikat innej witryny. W trakcie tego procesu dochodzi koniec końców do grupowania treści i klasyfikacji ich ważności. Na przykład poprzez odczytywanie sugestii w tagach rel=”canonical” lub rel=”alternate”.
Wyświetlanie wyników
Jeżeli chcemy, aby nasza strona internetowa osiągała satysfakcjonujące pozycje w bezpłatnych wynikach wyszukiwania, musimy również wziąć pod uwagę kondycję crawla, czyli tzw. crawl health. Brane są tutaj przede wszystkim pod uwagę aspekty techniczne, związane ściśle z szybkością ładowania witryny oraz czasem odpowiedzi serwera.
Stąd, jeśli nasza strona internetowa będzie osiągała satysfakcjonujący wynik pod kątem prędkości ładowania, możemy też oczekiwać, że będzie mogła być odpowiednio szybko indeksowana. Z kolei w sytuacji, gdy Googleboty zostaną zmuszone do długiego oczekiwania na odpowiedź serwera, mogą w trakcie jednej wizyty dodać do bazy danych mniej podstron. Co więcej, z tego też powodu w ich ocenie witryna może być traktowana jako mniej wartościowa, a co za tym idzie, nie powinna być wyświetlana na wysokich pozycjach w organicznych wynikach wyszukiwania.
Po drugie, warto także pamiętać o tzw. crawl demond, czyli o częstotliwości indeksacji. Ma to nierozerwalny związek z linkami prowadzącymi do witryny, które znajdują się na innych domenach zewnętrznych. Mogą one świadczyć o popularności danej strony internetowej wśród użytkowników. Innymi słowy, mowa tutaj o ilości osób, która ją odwiedza. Ponadto, na częstotliwość indeksacji ma również wpływ konsekwentne aktualizowanie zamieszczanych treści na stronie. Ponieważ na tego typu miejsca Googleboty mogą wchodzić o wiele częściej. A co za tym idzie, może mieć to przełożenie na wyższe pozycje witryny na wybrane frazy kluczowe w bezpłatnych wynikach wyszukiwania.
Zapisz się na newsletter i bądź na bieżąco z naszymi artykułami z bloga. Nie przegap najciekawszych naszych wpisów.
Administratorem udostępnionych przez Ciebie danych osobowych jest Ideo Force Sp. z o.o. Podanie danych osobowych jest dobrowolne, jednak ich niepodanie uniemożliwi świadczenie usług na Twoją rzecz. Dowiedz się więcej o zasadach przetwarzania Twoich danych osobowych oraz przysługujących Ci uprawnieniach w Polityce prywatności.
Czym zatem jest crawl budget?
Podsumowując, crawl budget, czyli budżet indeksowania, to nic innego, jak liczba podstron domeny, którą roboty sieciowe są w stanie zaindeksować. Lub też jest to czas oraz liczba zapytań, jakie Googleboty są wstanie zadać w kierunku witryny, w celu indeksacji danego adresu URL. Do głównych parametrów, które decydują o budżecie indeksowania, należą wspomniane wcześniej crawl demand (częstotliwość indeksacji), crawl health (kondycja crawla) oraz crawl rate limit (limit współczynnika indeksacji).
Budżet indeksowania – przydatne narzędzia
W tym miejscu omówimy przydatne narzędzia, które mogą ułatwić specjalistom zbieranie oraz analizowanie danych, związanych z budżetem indeksowania. A są to m.in.:
Google Search Console
W Google Search Console w przypadku analizy crawl budget bierzemy pod uwagę dwa raporty. Pierwszym jest tzw. „Stan indeksu”, który znany jest również jako Index Coverage. Raport ten jest z reguły bardzo obszerny. Jednakże zawarte w nim dane związane z adresami URL, które zostały wykluczone z ineksowania są dobrą okazją do tego, aby zrozumieć, z jakimi problemami przyjdzie nam się zmierzyć.
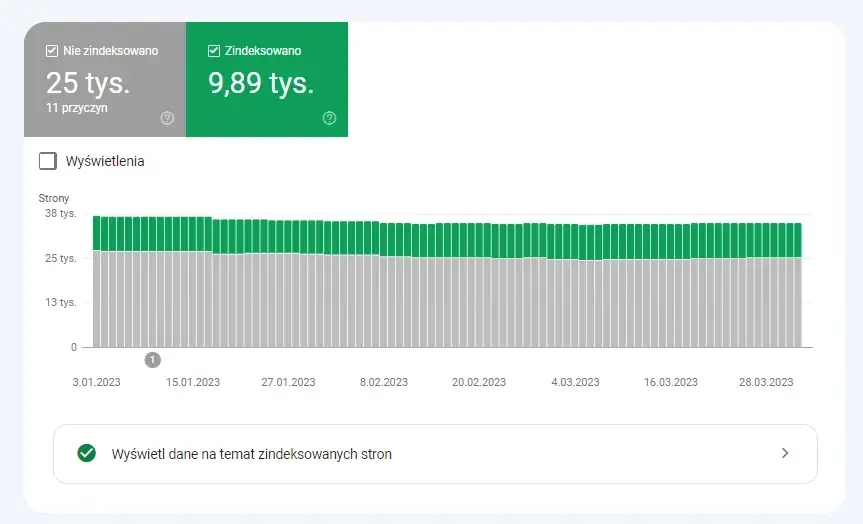
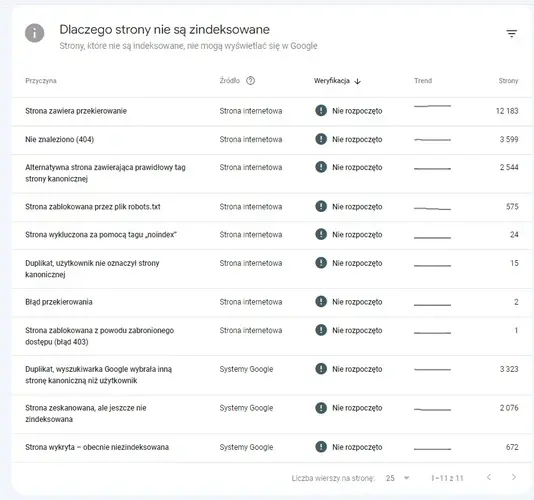
Źródło: Zrzut ekranu raportu „Stan indeksu” jednego z naszych klientów e-commerce
A mianowicie mowa tutaj m.in. o:
- Stronach wykluczonych za pomocą tagu „noindex”. Im więcej nasza domena ma podstron ze wspomnianym tagiem, tym mniej ruchu buduje.
- Strony zeskanowane, ale jeszcze niezaindeksowane. Warto w tym miejscu sprawdzić na przykład, czy witryna ma poprawnie zrenderowaną zawartość. Często takie podstrony mogą marnować crawl budget, gdyż nie przekładają się na zwiększenie ruchu organicznego.
- Duplikat, użytkownik nie oznaczył strony kanonicznej. Wszelkiego rodzaju duplikaty stron stanowią zagrożenie, ponieważ po pierwsze obniżają budżet indeksowania, a po drugie wzmagają ryzyko kanibalizacji fraz kluczowych.
- Duplikat, wyszukiwarka Google wybrała inną stronę kanoniczną niż użytkownik. Bardzo często wyszukiwarka internetowa decyduje o tym, jaki adres URL uznać za kanoniczny w sposób przypadkowy.
Drugim ważnym raportem w GSC pod kątem budżetu indeksowania, jest ten związany ze „Statystykami indeksowania”.
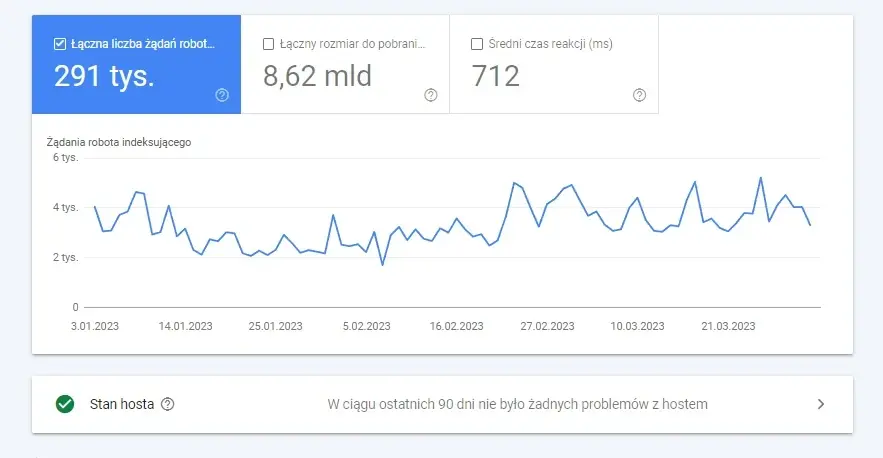
Źródło: Zrzut ekranu raportu „Statystyki indeksowania” jednego z naszych klientów e-commerce
W tym miejscu warto zwrócić uwagę na:
- Średni czas reakcji, który może informować o tym, że od jakiegoś czasu drastycznie się on wydłużył. A to z kolei może świadczyć o problemach, związanych z serwerem strony internetowej.
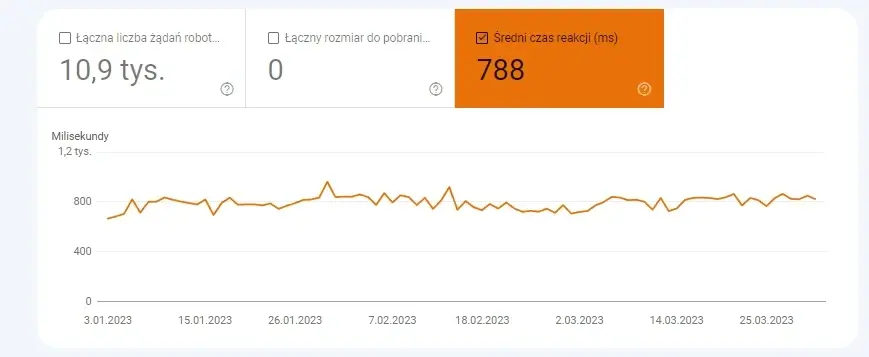
Zrzut ekranu raportu „Statystyki indeksowania” jednego z naszych klientów e-commerce
- Kody odpowiedzi HTTP/3xx, które świadczą o tym, że żądanie zostało przekierowane na inny adres URL. To z kolei, informuje nas o tym, że przeglądarka musi wysyłać nowe żądanie, aby uzyskać dostęp do żądanego zasobu. Nie wszystkie one są jednak wdrożone odpowiednio, przez co roboty sieciowe wielokrotnie marnują swój brawl budget.
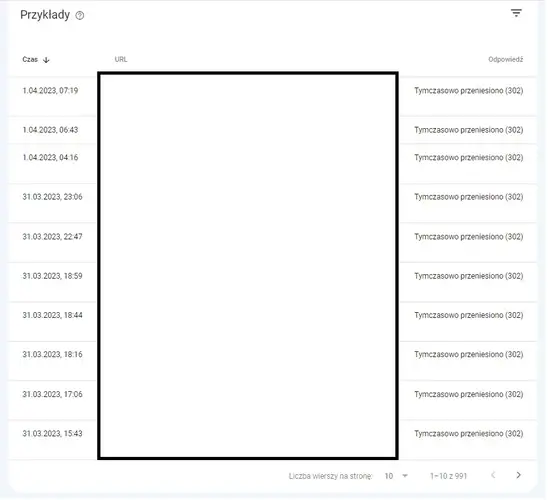
Zrzut ekranu raportu „Żądania indeksowania: Tymczasowo przeniesiono (302)” jednego z naszych klientów e-commerce
- Według przeznaczenia. W większości przypadków zawarte tu dane zależne są od tego, jak dużo nowych treści znajduje się na stronie.
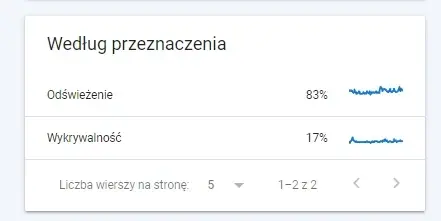
Zrzut ekranu raportu „Według przeznaczenia” jednego z naszych klientów e-commerce
- Screaming Frog - to tzw. crawler zewnętrzny, którego celem jest zasymulowanie tego, w jaki sposób roboty sieciowe poruszają się po stronie internetowej. Dzięki temu narzędziu możemy tak naprawdę zidentyfikować, czy wszystko, co dzieje się na stronie, jest tak, jak być powinno.
Zrzut ekranu wykonanego crawla witryny jednego z naszych klientów e-commerce
Warto w tym miejscu skorzystać z możliwości, jakie daje Screaming Frog i połączyć go z danymi Google Analitycs 4 oraz Google Search Console. W ten sposób możemy szybko zidentyfikować crawl budget waste, czyli na przykład adresy URL bez ruchu, które hipotetycznie mogą być zbyteczne.
Zrzut ekranu zakładki, gdzie można zintegrować dane z Google Analitycs 4 lub Google Serach Console
Senuto
Senuto jest narzędziem, które pozwala monitorować widoczność danych podstron w bezpłatnych wynikach wyszukiwania. Dzięki niemu wiemy np. które adresy URL są topowe. Innymi słowy mówimy tutaj o puli fraz kluczowych i ich pozycjach, jakie osiągają w TOP10, TOP20 i TOP50 organicznych wyników wyszukiwania.
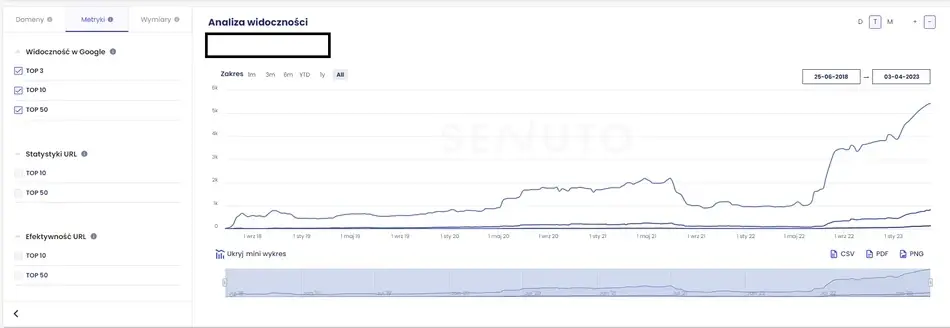
Zrzut ekranu widoczności w Google jednego z naszych klientów e-commerce
Interesują nas w tym narzędziu tak naprawdę dwa raporty, znajdujące się w „Analizie widoczności”, w zakładce „Sekcje” – „Ścieżki” oraz „URL-s”.
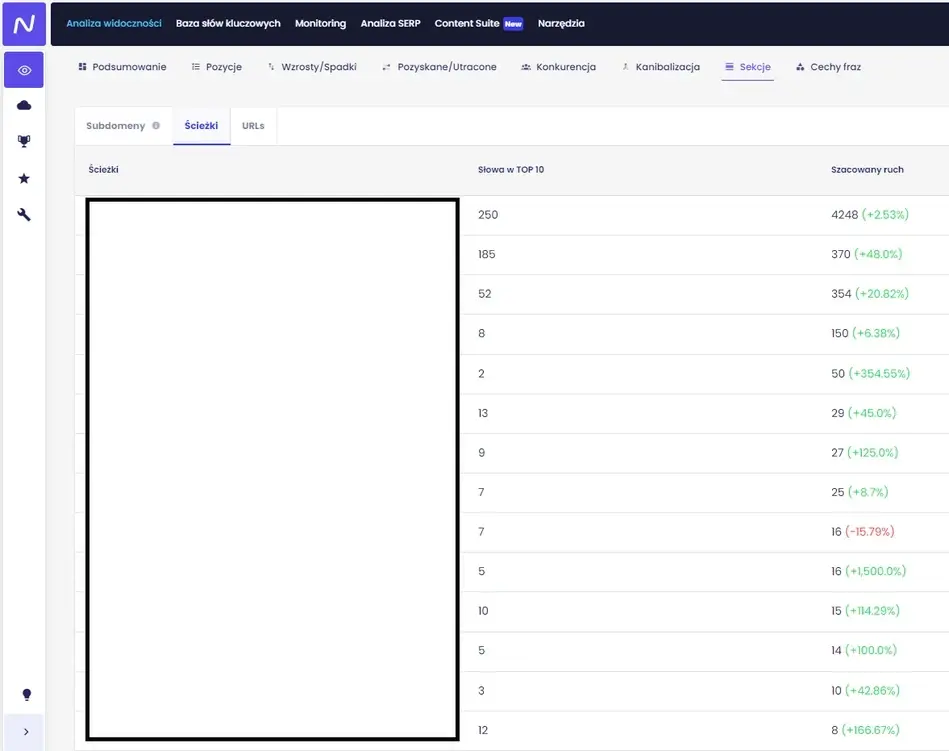
Raport „ Sekcje” – „Ścieżki” („Analiza widoczności) w narzędziu Senuto jednego z naszych klientów e-commerce
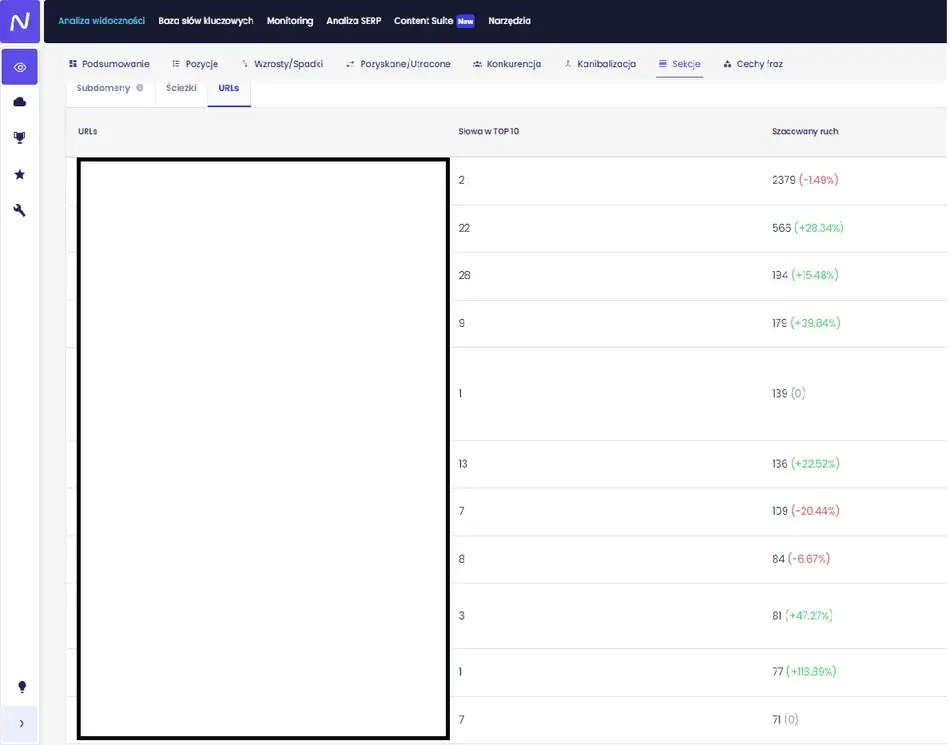
Raport „ Sekcje” – „URL-s” („Analiza widoczności) w narzędziu Senuto jednego z naszych klientów e-commerce
W tym miejscu powinien interesować nas zwłaszcza ten drugi raport. W końcu za pomocą opcji sortowania jesteśmy w stanie sprawdzić, jak wygląda kwestia fraz kluczowych, które zajmują od 1 do 10. pozycji w bezpłatnych wynikach wyszukiwania. A wszystko dlatego, że mogą one potencjalnie notować spory ruch organiczny. Powinniśmy w ten sposób kolejno zidentyfikować główną oś do symulacji budżetu crawlowania, a co za tym idzie, jego efektywnego wykorzystania.
Ahrefs
Ahrefs jest narzędziem, które pomaga zidentyfikować, jakie linki zwrotne prowadzą do naszej domeny. Stąd jeżeli posiadamy dużą pulę linków do konkretnego adresu URL, stanowi to okazje dla nas do optymalizacji crawl budżetu wokół niej. W ten sposób takie podstrony przyjmują rolę tzw. hubów, które przekazują moc dalej. Ponadto popularna podstrona ze sporą liczbą wartościowych linków, posiada szasnę na bycie skanowaną przez roboty sieciowe częściej.
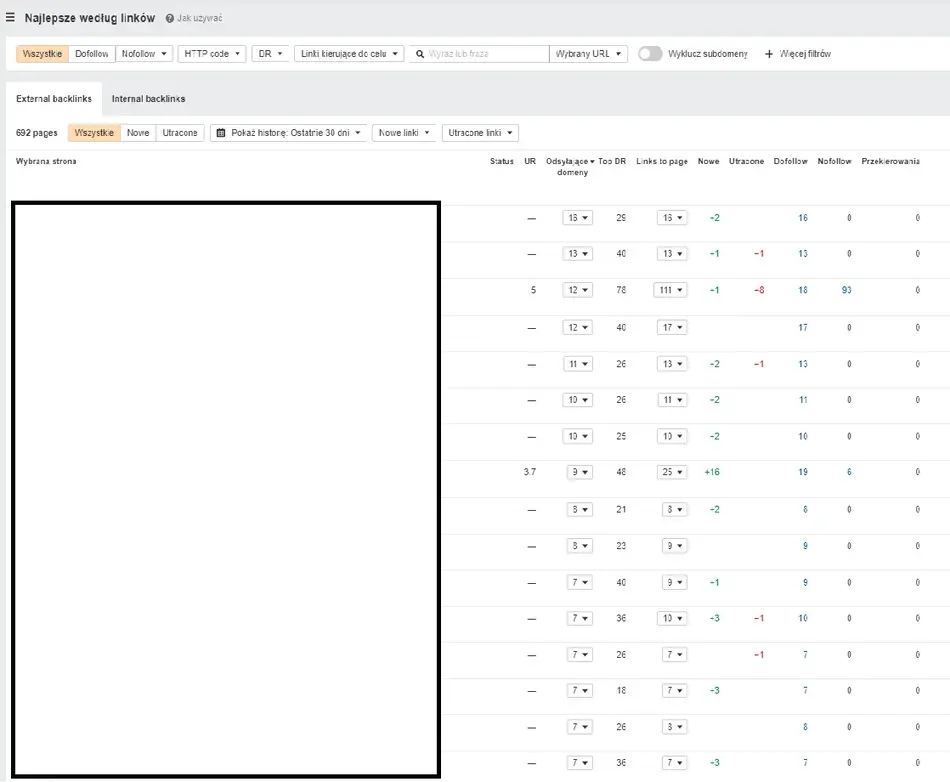
Raport „Strony” – „Najlepsze według linków” w narzędziu Ahrefs jednego z naszych klientów e-commerce
W raporcie „Strony” – „Najlepsze według linków” możemy zobaczyć adresy URL, które generują parametry z potencjałem w zakresie ilości linków przychodzących w ramach konkretnej podstrony. Takie miejsca mogą zdobywać duże zainteresowanie wśród Googlebotów, a co za tym idzie, przekazywać/kierować moc dalej, w głąb witryny.
Streszczenie
- Budżet crawlowania jest ściśle związany z pozyskiwaniem, indeksowaniem i organizacją informacji przez Google, co ma wpływ na pozycjonowanie danej strony internetowej w organicznych wynikach wyszukiwania.
- Wyszukiwarka Google skanuje strony internetowe za pomocą robotów sieciowych, które analizują treść i pobierają zasoby witryny, a następnie renderuje ją, oceniając m.in. zawartość, strukturę czy layout.
- Aby przeskanowanie domeny było możliwe, Google musi mieć świadomość jej istnienia, co może osiągnąć dzięki linkom z innych stron internetowych znajdujących się w indeksie, lub dzięki Sitemap przekazanej za pośrednictwem Google Search Console.
- Podczas procesu indeksowania roboty sieciowe zbierają informacje ze strony internetowej m.in. o treściach, linkach i grafikach i zapisują je w bazie danych. A następnie oceniają wartość, jaką niesie za sobą dana witryna.
- Adresy URL są indeksowane pojedynczo, a crawl budżet zależy od czasu, jaki roboty mogą poświęcić na indeksowanie, dlatego ważne jest zadbanie o optymalizację elementów, takich jak: nawigacja, unikanie duplikatów, usuwanie błędów 404, publikowanie wartościowej treści, wyłączanie indeksowania podstron o znikomym znaczeniu, pod kątem optymalizacji i pozycjonowania.
- Googleboty grupują treści i klasyfikują ich ważność na podstawie odczytanych sugestii, takich, jak na przykład tag rel=”canonical” lub rel=”alternate”.
- Aby nasza strona osiągała dobre pozycje w wynikach wyszukiwania, musimy dbać o kondycję crawla, czyli aspekty techniczne, takie jak, szybkość ładowania strony i czas odpowiedzi serwera.
- Kiedy strona działa sprawnie, jest szybciej indeksowana przez Google i zyskuje wartość w ocenie wyszukiwarki, co może przyczynić się do wyższych pozycji. Ważne jest także zadbanie o linki prowadzące do naszej strony oraz systematyczne aktualizowanie treści.
- Narzędziami wspomagającymi optymalizację budżetu crawlowania są m.in. Ahrefs, Senuto, Screaming Frog czy Google Search Console.
Podsumowanie
Crawl budget to złożone oraz często niejasne pojęcie dla wielu z nas, które ma związek z procesem skanowania i indeksowania strony przez roboty wyszukiwarek. Jego wynik ma tak naprawdę przełożenie na ostateczną klasyfikację witryny w bezpłatnych wynikach wyszukiwania. Stąd budżet indeksowania może tak naprawdę dotyczyć zarówno małych, jak i dużych witryn, na które możemy się natknąć na co dzień, przeszukując zasoby Internetu.
