Indeksowanie a widoczność strony w wynikach wyszukiwania (SERP)
Indeksowanie jest ściśle powiązane z widocznością strony w wynikach wyszukiwania, czyli w tzw. SERP (Search Engine Results Pages) i odgrywa istotną rolę w efektywnym funkcjonowaniu stron internetowych. Proces ten umożliwia wyszukiwarkom skuteczne lokalizowanie i wyświetlanie odpowiednich wyników zgodnych z zapytaniami użytkowników. Warto jednak zaznaczyć, że samo zaindeksowanie strony nie gwarantuje tego, że zostanie ona wyświetlona na wysokich pozycjach w wynikach wyszukiwania. Jest to jedynie niezbędnym warunkiem do tego, by w ogóle mogła pojawić się w wynikach.
Poprawne indeksowanie pełni kluczową rolę w zwiększeniu widoczności strony w sieci, a także w przyciąganiu do niej ruchu organicznego. Strony, które nie zostały zaindeksowane, nie pojawią się w SERP, co oznacza dla nich brak ruchu z wyników wyszukiwania.
Jak działa proces indeksowania?
Sieć internetowa to rozległa przestrzeń, w której codziennie powstaje mnóstwo nowych stron i treści. Z powodu tak ogromnej ilości informacji dostępnych online, zaindeksowanie wszystkich witryn jest niemożliwe. Dlatego powstały zaawansowane algorytmy, których zadaniem jest zoptymalizowanie zasobów używanych przez wyszukiwarki i wybieranie tylko tych stron, które zasługują na miejsce w indeksie.
Te zaawansowane algorytmy decydują, jakie strony zostaną zindeksowane i w jaki sposób będą prezentowane w wynikach wyszukiwania. Ich głównym celem jest dostarczenie użytkownikom jak najbardziej trafnych i wartościowych wyników. Są one w stanie analizować wiele czynników, takich jak np. jakość treści, struktura strony, linki, użyteczność i wiele innych, aby ocenić, czy dana witryna powinna zostać zindeksowana oraz, jak wysoko powinna pojawić się w wynikach wyszukiwania.
Ważne jest także to, aby zauważyć, że algorytmy wyszukiwarek, takie jak ten wykorzystywany przez Google, są stale aktualizowane i doskonalone, aby poprawić jakość wyników wyszukiwania oraz zapobiegać manipulacjom. Dlatego osoby zajmujące się optymalizacją stron pod kątem SEO muszą być na bieżąco z najnowszymi aktualizacjami i dostosowywać swoje strategie tak, aby pozycjonowane przez nie strony mogły zyskać wysokie pozycje w wynikach wyszukiwania.
Kluczowym czynnikiem wpływającym na proces indeksowania jest optymalizacja strony. Dobre praktyki SEO, takie jak zoptymalizowany kod, unikalne oraz wartościowe treści, przyjazna dla użytkowników struktura linków i odpowiednia budowa strony, mogą znacznie zwiększyć szanse na osiągnięcie wysokich pozycji w wynikach wyszukiwania. Dlatego warto inwestować w solidne SEO, aby w pełni wykorzystać potencjał swojej strony i dotrzeć do jak największej liczby użytkowników.
Etapy indeksowania strony przez wyszukiwarkę Google
Proces indeksowania, czyli sposób, w jaki wyszukiwarki odnajdują i organizują informacje, opiera się na działaniu robotów wyszukiwarek, zwanych również botami. Są to zaawansowane programy komputerowe, które pełnią istotną rolę w przeszukiwaniu stron internetowych i zbieraniu danych do spójnego indeksu.
Pierwszy z etapów „poznawania” stron przez wyszukiwarki odpowiada za skanowanie, podczas którego roboty wyszukują treść stron internetowych, do których prowadzą linki, tworząc pomiędzy nimi ogromną sieć połączeń. Dzięki temu mogą dotrzeć do nowych miejsc, aby następnie zdecydować czy warto zindeksować informacje. Gdy boty odwiedzają stronę, analizują jej kod HTML oraz pozostałe elementy, takie jak tytuł, tekst, obrazy i pliki video. Szczególną uwagę zwracają na treść tekstową, ponieważ stanowi ona źródło informacji, kluczowe dla odpowiedniego indeksowania strony.
Ważnym etapem procesu indeksowania jest spełnienie wymagań technicznych ustalonych przez Google. Przede wszystkim, strona musi być dostępna dla robotów wyszukiwarek. Tym samym nie można blokować im do niej dostępu, ani za pomocą pliku robots.txt, meta tagu „robots” czy też w żaden inny sposób. Dodatkowo konieczne jest to, aby witryna działała poprawnie, co oznacza, że po jej odwiedzeniu, Googlebot musi otrzymać kod stanu HTTP 200 (success). Znacznym utrudnieniem w procesie indeksowania strony, jest brak treści, którą roboty mogłyby „zauważyć”. Content ukryty za formularzami logowania, obrazami bez tekstu alternatywnego czy treściami generowanymi dynamicznie przez JavaScript, stanowi dużą przeszkodę, ale nie zamyka „drzwi” przed robotami.
Jednak samo spełnienie tych wymagań technicznych nie gwarantuje, że strona zostanie zindeksowana i wyświetlana w wynikach wyszukiwania. Należy przestrzegać także zasad, dotyczących spamu i wyznaczonych przez Google, które mają na celu eliminację stron naruszających ogólne warunki wyszukiwania. Dlatego ważne jest unikanie działań, takich jak:
- maskowanie,
- tworzenie stron doorway,
- umieszczanie ukrytego tekstu i linków,
- nadmierne używanie słów kluczowych, spamowanie linkami, sztuczne generowanie ruchu komputerowego,
- rozpowszechnianie złośliwego oprogramowania,
- zachowania wprowadzające w błąd,
- uczestniczenie w afiliacjach bez wartości dodanej,
- kopiowanie treści, stosowanie niejawnych przekierowań, publikowanie spamu generowanego automatycznie,
- zachęcanie użytkowników do tworzenia spamu,
- nielegalne usuwanie danych osobowych, omijanie zasad lub podejmowanie prób oszustw.
Aby zwiększyć widoczność strony w wynikach wyszukiwania, warto skorzystać także ze sprawdzonych metod tworzenia stron rekomendowanych przez Google. Kluczowym czynnikiem jest tworzenie unikalnej treści o wysokiej jakości. Należy również dbać o odpowiednie wykorzystywanie tytułów, nagłówków oraz zapewnić teksty alternatywne dla obrazów. Należy zezwolić także na indeksowanie linków. Dodatkowo, dzielenie się treściami ze swojej witryny w mediach społecznościowych, również może przyczynić się do zwiększenia jej widoczności.
Proces indeksowania strony przez Google obejmuje 4 etapy:
- Skanowanie (crawlowanie) – roboty wyszukiwarek przeglądają strony internetowe, aby odkryć nowe treści oraz zaktualizować istniejące. Ten proces, nazywany również „wykrywaniem adresów URL”, polega na skanowaniu zarówno strony głównej, jak i jej podstron. Crawlery analizują strukturę witryny, przechodzą przez odnośniki i pobierają tekst, obrazy oraz filmy, które zostaną zidentyfikowane na stronach. Googlebot stosuje ustalone algorytmy, aby wybrać strony, które zostaną poddane indeksowaniu. Określa także, jak często powinny być ponownie sprawdzane oraz ile podstron z danej witryny należy pobrać. Warto zaznaczyć, że roboty wyszukiwarek zostały zaprogramowane tak, aby unikać zbyt szybkiego indeksowania witryn, co mogłoby prowadzić do przeciążenia serwerów. Skanowanie zależy od dostępności Googlebota dla danej witryny, a ograniczenia w dostępie mogą wynikać z problemów z serwerem, siecią lub ograniczeń ustawionych w pliku robots.txt, uniemożliwiających robotowi dostęp do treści.
- Renderowanie – po pobraniu zawartości strony, crawler analizuje kod HTML, CSS i JavaScript, wykorzystując najnowszą wersję przeglądarki Chrome. Wiele stron korzysta z JavaScriptu do dynamicznego ładowania treści, a poprawne renderowanie jest niezbędne, aby Googlebot mógł je zobaczyć.
- Indeksowanie – na tym etapie dochodzi do przetwarzania i analizy różnych elementów zawartości strony, takich jak treść tekstowa, kluczowe tagi i atrybuty (np. elementy (title)). Googlebot sprawdza także, czy strona nie jest duplikatem innej witryny w Internecie lub stroną kanoniczną (referencyjną). Podczas indeksowania gromadzone są sygnały dotyczące strony kanonicznej i jej zawartości, które mają wpływ na kolejny etap – wyświetlanie strony w wynikach wyszukiwania. Te sygnały obejmują informacje, takie jak np. język strony czy kraj, do którego treść jest skierowana. W trakcie tego procesu mogą pojawić się różne problemy, takie jak np. niska jakość treści na stronie, zastosowanie reguł meta Robots (zabraniających indeksowania), czy też projekt strony, utrudniający proces indeksowania.
- Rankowanie – po zakończeniu, strony są gotowe do wyświetlania w wynikach wyszukiwania. Kiedy użytkownik wpisuje zapytanie w wyszukiwarkę, algorytm analizuje indeks, aby znaleźć strony odpowiednie dla danego zapytania. Następnie użytkownik otrzymuje zestaw wyników, który najlepiej odpowiada jego zapytaniu. W procesie wyboru uwzględniane są różnorodne czynniki, takie jak trafność, popularność i inne elementy rankingowe.
Jak często Google indeksuje strony?
Google stale przegląda i indeksuje strony, jednak nie istnieje ustalona częstotliwość, z którą boty odwiedzają witryny. Częstotliwość indeksowania zależy od różnych czynników, z których jeden to tzw. crawl budget, określający, ile i jak często boty będą odwiedzać daną stronę.
Kluczowe metody optymalizacji crawl budgetu obejmują m.in. redukcję wskaźników time to first byte oraz time to last byte. Ważne jest także usunięcie zdublowanych treści, pozbycie się contentu niskiej jakości, naprawienie błędów HTTP (np. błędy 5xx, 4xx, 3xx i przekierowania klienta), poprawienie linkowania wewnętrznego czy aktualizowanie mapy XML.
Częstotliwość indeksowania zależy również od:
- nowości strony,
- częstotliwości wprowadzenia zmian na stronie,
- popularności witryny,
- rozmiaru witryny – duże witryny z wieloma stronami mogą być indeksowane partiami,
- obecności linków zewnętrznych.
Jeśli Googleboty odwiedziły witrynę po raz pierwszy, to mogą ponownie do niej wrócić, aby przeanalizować stronę pod kątem nowej zawartości, nawet w przeciągu najbliższych godzin. Ważne jest, aby zapewniać lepszą jakość oraz aktualizować treści, co z kolei sprawia, że roboty chętniej i częściej będą odwiedzać stronę internetową.
Ile czasu potrzeba, aby Google zaindeksowało stronę tak, aby była widoczna w wynikach wyszukiwania?
Odwiedziny bota można „wymusić” z pomocą narzędzia Google Search Console. Czas pierwszego zaindeksowania w największym stopniu zależy od tego, jak szybko zostaną dostarczone odnośniki do strony, czyli utworzy się ścieżka, po której boty będą mogły do niej dotrzeć. Czas indeksowania strony, a tym samym jej pojawienia się w organicznych wynikach wyszukiwania, zależy od częstotliwości skanowania, przypisanej do witryny. W dużym uproszczeniu jest więc zależny od tego, jak często Googleboty wchodzą na stronę oraz od głębokości, z jaką ją skanują. Od 2021 roku czas indeksowania został wydłużony, co oznacza, że może to potrwać godzinę, kilka godzin, wiele dni czy nawet miesięcy. Działania z zakresu pozycjonowania strony, potrafią jednak przyspieszyć indeksację.
Jak sprawdzić, czy strona jest zaindeksowana?
Istnieje kilka sposobów, aby sprawdzić, czy strona została zaindeksowana przez roboty wyszukiwarek. Jednym z nich jest użycie komendy „site:nazwadomeny” w wyszukiwarce Google, np. „site:ideoforce.pl”. Trzeba jednak pamiętać, że ta metoda nie zawsze wskazuje dokładne wyniki indeksacji. Inną opcją jest skorzystanie z narzędzi, takich jak Google Search Console (GSC). Wystarczy zalogować się do panelu GSC i wpisać adres strony internetowej w górnym polu, a jeśli wyświetli się komunikat: „Adres URL znajduje się w Google”, oznacza to, że strona została zindeksowana. Również w GSC, w raporcie: „Indeksowanie – Strony” można znaleźć dokładny stan indeksacji danej witryny. Oprócz tego istnieją specjalistyczne narzędzia w wersji płatnej, takie jak Semrush, Ahrefs czy Moz, które dostarczają szczegółowych informacji na temat indeksacji strony.
Jak można wpłynąć na przyspieszenie indeksacji?
Istnieje kilka działań, które mogą przyspieszyć indeksację strony przez roboty wyszukiwarki. Pierwszym krokiem jest utworzenie mapy witryny (sitemap) i przesłanie jej do Google Search Console w zakładce „Indeksowanie – Mapy witryny”. Wysłanie zaktualizowanej mapy po dokonaniu zmian na stronie może przyspieszyć proces indeksacji. Kolejną opcją jest skorzystanie z funkcji „Prośba o zindeksowanie” w Google Search Console. Należy jednak pamiętać, że to jedynie sugestia dla Google, a zaindeksowanie strony może nastąpić z opóźnieniem lub prośba w ogóle nie musi zostać uwzględniona.
Innym sposobem na przyspieszenie indeksacji jest skorzystanie z Indexing API od Google, które pozwala powiadomić Google o nowych lub zmodyfikowanych stronach. Kluczowe jest również zastosowanie linkowania wewnętrznego, czyli umieszczanie wewnętrznych linków prowadzących do nowych lub istotnych stron, które mają zostać zaindeksowane. Googleboty często odkrywają nowe strony, właśnie poprzez śledzenie linków.
Należy pamiętać o tym, by zapewnić botom pełen dostęp do witryny, co umożliwi im skuteczną indeksację. Trzeba więc unikać blokowania dostępu z pomocą pliku robots.txt lub tagów meta noindex/nofollow. Optymalizacja strony odgrywa kluczową rolę w przyspieszeniu tego procesu. Istnieje kilka czynników, które mogą wpłynąć na indeksację. Dodatkowo regularne publikowanie wartościowej treści, poprawa crawl budgetu strony, stworzenie crawler-friendly struktury witryny (zapewnienie łatwego dostępu do treści strony, tworzenie czytelnej struktury URL oraz przygotowanie poprawnego mapowania nawigacji) może ułatwić botom indeksowanie witryny.
Problemy przy indeksowaniu stron internetowych
Rozwiązanie problemów z indeksacją rozpoczyna się od analizy potencjalnych problemów na stronie oraz systematycznej analizy logów serwera. Pliki logów zawierają pełne i precyzyjne informacje o działaniach na serwerze, które nie podlegają filtracji, katalogowaniu czy próbkowaniu. Dzięki analizie logów możliwe jest śledzenie zachowania wyszukiwarki Google, w tym częstotliwości odwiedzin oraz stanu odpowiedzi witryny. Ta metoda pomaga w zrozumieniu sposobu działania botów, w tym zidentyfikowaniu stron, które są odwiedzane.
Analiza logów serwera stanowi nieocenioną pomoc zarówno podczas procesu indeksacji, jak i w wykrywaniu błędów indeksowania. Przykładowo, umożliwia sprawdzenie, czy boty mają problemy z dostępem do konkretnych stron, jeżeli ich żądania nie zostały pomyślnie zaimplementowane. Ponadto można monitorować częstotliwość indeksacji, by określić, kiedy boty odwiedzają stronę. Narzędziem, które znakomicie wspomaga analizę logów serwera, jest SEO Log File Analyzer, udostępniany przez firmę Screaming Frog.
W Google Search Console w zakładce „Indeksowanie – Strony” dostępne są informacje, dotyczące stanu indeksacji strony internetowej. Na samej górze tej sekcji prezentowana jest liczba podstron znajdujących się w indeksie wyszukiwarki Google. Obok niej widoczne są również URL-e, które z różnych powodów nie zostały uwzględnione w indeksie tej popularnej wyszukiwarki. Analiza tych danych również jest nieocenioną pomocą w rozwiązywaniu problemów z indeksowaniem strony.
Na liście przyczyn braku indeksacji, można znaleźć komunikaty, takie jak m.in.:
- „Strona zawiera przekierowanie” – informacja ta oznacza, że adres URL przekierowuje do innego adresu, przy użyciu kodu 3xx. W wynikach wyszukiwania może pojawić się adres docelowy, który nie musi trafić do indeksu Google, choć jest taka możliwość.
- „Strona wykluczona za pomocą tagu 'noindex’” – komunikat ten informuje o tym, że w czasie indeksacji Googlebot napotkał regułę „noindex” w znaczniku „meta robots” lub w tożsamym nagłówku odpowiedzi HTTP. To spowoduje z kolei, że witryna zostanie całkowicie wyeliminowana z wyników wyszukiwania w Google.
- „Alternatywna strona zawierająca prawidłowy tag strony kanonicznej” – informacja ta oznacza, że istnieją 2. takie same lub bardzo podobne pod względem zawartości strony, ale są umieszczone pod różnymi adresami URL, przy czym jedna stanowi duplikat drugiej i został na niej umieszczony canonical tag. Jeżeli tag kanoniczny jest poprawnie skonfigurowany i wskazuje na oryginalną wersję strony, to duplikat nie powinien zostać uwzględniony w indeksie. Warto sprawdzić, czy „adres kanoniczny określony przez użytkownika” właściwie wskazuje na oryginalną wersję strony.
- „Duplikat, wyszukiwarka Google wybrała inną stronę kanoniczną niż użytkownik” – komunikat ten wskazuje na to, że pomimo wybrania przez użytkownika strony kanonicznej dla danego adresu URL (lub grupy adresów), wyszukiwarka Google zdecydowała się na wybranie innej strony, którą uznała za bardziej odpowiednią. Taka sytuacja często wynika z niewielkich różnic w zawartości pomiędzy wskazanym adresem URL a stroną, która się do niego odnosi.
- „Duplikat, użytkownik nie oznaczył strony kanonicznej” – gdy ten komunikat pojawia się w GSC, oznacza to, że na stronie występują duplikaty, a użytkownik nie skonfigurował odpowiednich linków kanonicznych dla zduplikowanej wersji strony.
- „Nie znaleziono (404)” – komunikat ten informuje o tym, że dany adres URL nie istnieje, został zmieniony na inny lub zawiera literówkę i należy rozważyć czy ustawić przekierowanie 301 czy zostawić błąd.
- „Strona zablokowana z powodu innego błędu 4xx” – wskazuje na inne błędy związane z kodami 4xx, ale innymi niż 404, 401 i 403, tak jak w przypadku serwera 5xx.
- „Pozorny błąd 404” – oznacza rozbieżności pomiędzy tym, co widzi użytkownik, a tym, co wykrył robot Google. Warto sprawdzić, czy adresy z listy wyświetlają się prawidłowo. Trzeba to zweryfikować np. w momencie, w którym adres zwraca kod 200, a użytkownicy nie widzą strony.
- „Strona wykryta – obecnie nie zindeksowana” – komunikat ten informuje, że strona została już znaleziona, ale jeszcze nie jest zindeksowana przez Google. Może to wynikać z przeciążenia witryny, przerwania procesu lub zaplanowania indeksacji na później. Data ostatniego indeksowania w raporcie może być pusta, a to oznacza, że adres URL czeka na zaindeksowanie w kolejce.
- „Strona zeskanowana, ale jeszcze nie zaindeksowana” – oznacza, że strona została zeskanowana, jednak nie została jeszcze zaindeksowana przez Google. W tym przypadku nie ma potrzeby ponownego przesyłania adresu URL do zeskanowania, gdyż został on właściwie przenalizowany, lecz nie jest uwzględniony w indeksie. Jego indeksacja nastąpi za jakiś czas. Można ją przyspieszyć, stosując linkowanie wewnętrzne, zewnętrzne czy indeksery.
- „Strona zablokowana przez plik robots.txt” – komunikat ten wskazuje, że strona przesłana do zaindeksowania jest zablokowana w pliku robots.txt, a to ogranicza indeksację. Taka sytuacja powoduje powstanie błędu, ponieważ wysłane jednocześnie prośby i dyrektywy wykluczają się nawzajem. Jeśli adres URL ma trafić do indeksu, należy usunąć komendę blokującą z pliku robots.txt.
W Google Search Console w zakładce „Strony” w kolumnie „Przyczyna” można odnaleźć listę/wykaz powodów braku indeksacji. Obok tej listy znajduje się również kolumna „Źródło”. Jeśli wskazana jest „Strona internetowa” to oznacza, że problem leży właśnie po jej stronie, natomiast jeśli widnieje informacja „Systemy Google”, to trudności wystąpiły po stronie Google. W zakładce „Menu – Indeksowanie – Strony filmów” można znaleźć informacje o stanie indeksacji plików wideo, które zostały umieszczone w witrynie.
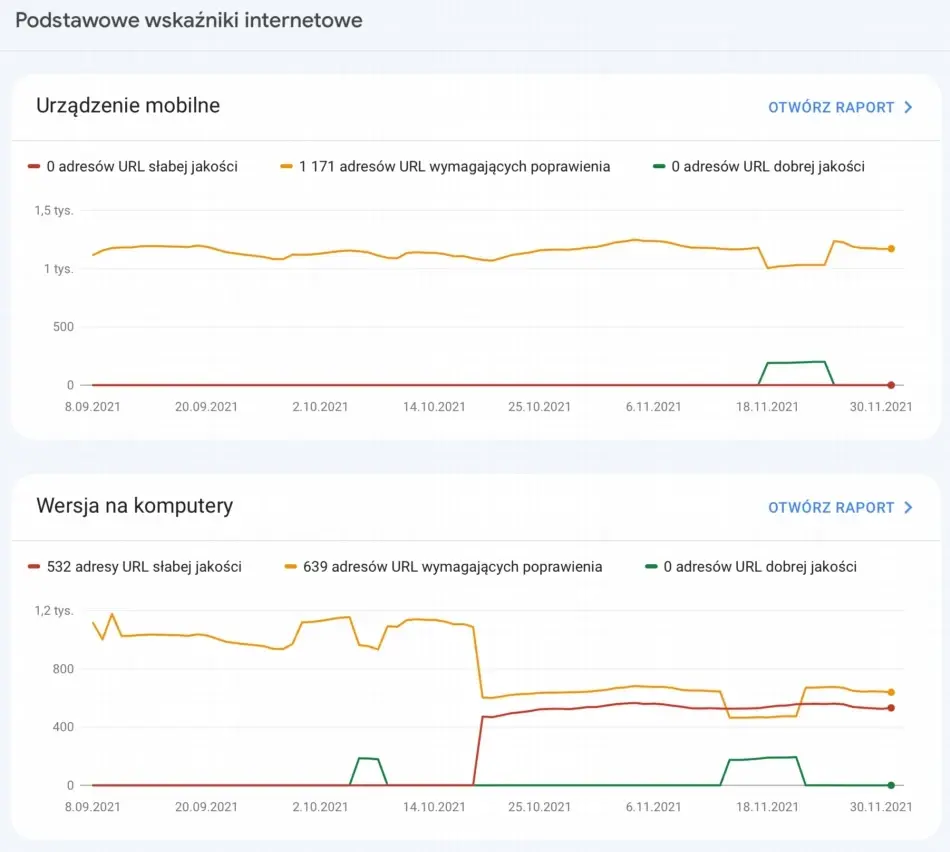
Czynniki wpływające na problemy z indeksacją
Wyróżnia się 4 główne czynniki, które mogą utrudnić indeksowanie strony przez wyszukiwarki. Zalicza się do nich:
Błędy techniczne strony – to m.in. niedziałające linki, błędy serwera, powolne wczytywanie strony lub nieprawidłowo zaimplementowany kod. Mogą one negatywnie wpływać na indeksację. Tego typu błędy można podzielić na:
- Błędy kodu HTML i CSS – mogą prowadzić do problemów z indeksacją strony. Dlatego ważne jest zastosowanie się do kilku wskazówek, dotyczących poprawnego stosowania znaczników HTML i CSS. Należy upewnić się, że wszystkie tagi HTML są poprawnie zamknięte, a kod jest zgodny z najnowszymi standardami. Niepoprawnie zapisane lub zamknięte tagi mogą utrudnić robotom indeksację strony, czy nawet prowadzić do błędów w wyświetlaniu treści. Narzędzia do weryfikacji poprawności kodu, takie jak W3C Markup Validation Service, mogą być użyteczne przy identyfikowaniu i naprawianiu błędów w kodzie.
- Problemy z dostępem do treści – czasami niektóre elementy strony mogą być niedostępne dla robotów wyszukiwarek z powodu błędnej konfiguracji pliku robots.txt lub innych czynników. Tymczasem roboty wyszukiwarek potrzebują dostępu do treści, by móc zaindeksować witrynę. Dlatego ważne jest to, aby monitorować logi serwera i zidentyfikować ewentualne problemy z dostępem do treści.
- Zbyt wolne ładowanie witryny – czynnik ten może mieć negatywny wpływ zarówno na indeksację, jak i na UX. Jeśli strona cechuje się długim czasem ładowania, roboty wyszukiwarek mogą potrzebować więcej czasu na przeszukanie całej witryny, co prowadzi do rzadszych odwiedzin i spowolnienia procesu indeksacji. Dodatkowo użytkownicy nie lubią długo czekać na załadowanie strony, co może być przyczyną wysokiego współczynnika odrzuceń. Optymalizacja czasu ładowania strony (np. poprzez kompresję obrazów, minimalizację kodu HTML i CSS oraz zastosowanie technik buforowania), może poprawić zarówno indeksację, jak i doświadczenia użytkownika.
Problemy z treścią – niewłaściwie zoptymalizowana lub nieprzyjazna dla wyszukiwarek treść może powodować problemy z indeksacją. Do problemów z treścią zalicza się m.in.:
- Duplikacja – może mieć negatywny wpływ na indeksację i optymalizację strony pod kątem SEO. Roboty indeksujące mogą tracić czas i zasoby na indeksowanie tych samych treści. Ważne jest, aby unikać duplikacji, poprzez stosowanie canonical tags, wskazujących preferowaną wersję strony.
- Niska jakość treści – dostarczanie unikalnej i wartościowej treści jest kluczowe dla skutecznej indeksacji strony. Słabej jakości treść może wpływać na rzadsze odwiedziny robotów wyszukiwarek. Ważne jest, aby dbać o jakość treści, które przyciągają zarówno roboty wyszukiwarek, jak i użytkowników. Dobrej jakości treść, bogata w informacje i odpowiednio zoptymalizowana pod względem słów kluczowych, może przyczynić się do lepszej widoczności strony w wynikach wyszukiwania.
- Brak odpowiedniej optymalizacji słów kluczowych – brak optymalizacji słów kluczowych może utrudniać indeksację strony dla odpowiednich zapytań. Wyszukiwarki są coraz bardziej „skoncentrowane” na intencjach wyszukiwania użytkowników, dlatego ważne jest, aby zoptymalizować stronę pod kątem słów kluczowych, związanych z treściami i potrzebami internautów.
Problemy z linkami i strukturą witryny – niewłaściwie zbudowana struktura witryny i problemy z linkami mogą powodować problemy z indeksacją. Do problemów tych zalicza się zwłaszcza:
- Uszkodzone lub nieprawidłowe linki – prowadzą do błędnych stron lub wywołują błędy 404, co utrudnia robotom przeszukiwanie witryny. Regularne monitorowanie linków i usuwanie lub naprawianie uszkodzonych, jest ważnym krokiem w utrzymaniu „zdrowej” struktury witryny i skutecznej indeksacji.
- Błędna struktura URL – niewłaściwa struktura URL może wpływać zarówno na indeksację, jak i na czytelność strony. Warto stosować optymalizację struktury URL, aby adresy były zrozumiałe zarówno dla użytkowników, jak i dla robotów wyszukiwarek. Należy unikać nadmiernie skomplikowanych parametrów w adresach i starać się używać zrozumiałych słów kluczowych, opisujących zawartość strony. Dobrze zoptymalizowane adresy URL ułatwiają indeksację witryny i mogą przyczynić się do lepszych wyników w wyszukiwarkach.
- Niewłaściwe wykorzystanie canonical tags – linki kanoniczne są ważnym narzędziem wskazującym preferowaną wersję strony, zwłaszcza w przypadku stron o podobnej lub identycznej treści. Nieprawidłowe stosowanie canonical tags może prowadzić do problemów z indeksacją. Ważne jest, aby poprawnie umieszczać tagi i monitorować ich działanie.
Błędy w plikach robots.txt i sitemap – błędy te mogą uniemożliwiać pełne zrozumienie struktury witryny przez roboty wyszukiwarek. Zalicza się do nich zwłaszcza:
- Brak pliku robots.txt lub nieprawidłowa konfiguracja – plik robots.txt ma istotne znaczenie dla procesu indeksacji. Jego poprawna konfiguracja pozwala na kontrolowanie dostępu robotów wyszukiwarek do różnych części witryny. Jeśli plik robots.txt jest nieobecny lub nieprawidłowo skonfigurowany, może to prowadzić do problemów z indeksacją. Ważne jest więc to, by plik robots.txt był tworzony zgodnie z zasadami.
- Nieprawidłowa mapa strony (sitemap) lub jej brak – sitemap odgrywa istotną rolę w procesie indeksacji strony. Pomaga robotom wyszukiwarek w przeszukiwaniu i indeksowaniu różnych podstron w witrynie. Warto stworzyć mapę strony w formacie XML i przesłać ją do narzędzi dla webmasterów, takich jak Google Search Console oraz Bing Webmaster Tools. Mapa strony powinna zawierać istotne URL-e, hierarchię stron, priorytety i częstotliwość aktualizacji. Ponadto, jeśli na stronie znajdują się obrazy i filmy, warto utworzyć dla nich oddzielną mapę strony. Jej regularne monitorowanie i aktualizowanie, wraz z ewentualnymi zmianami struktury witryny pomaga w utrzymaniu efektywnej indeksacji.
Audyt techniczny strony
Audyt techniczny strony jest niezwykle istotnym narzędziem dla wszystkich właścicieli witryn internetowych, którzy pragną utrzymać wysoką widoczność w wynikach wyszukiwania. Przeprowadzenie takiego audytu pozwoli wykryć wszelkie problemy techniczne, które mogą mieć negatywny wpływ na indeksację strony przez wyszukiwarki. Dlatego warto regularnie wykonywać lub zlecać taki audyt w celu monitorowania stanu technicznego witryny. Cykliczne przeprowadzanie takiego audytu, aktualizacja treści i monitorowanie plików, pomoże zapobiegać problemom z indeksacją w przyszłości. Dlatego warto inwestować czas i zasoby w audyt techniczny, aby zyskać pewność, że strona jest optymalnie zindeksowana i osiąga pożądane wyniki w wyszukiwarkach.
Indeksowanie mobile first (mobile first index)
Indeksowanie mobile first (mobile first indexing) stało się kluczowym elementem strategii pozycjonowania witryn internetowych. Obecnie nie tylko strony mobile mają pierwszeństwo w procesie cyklicznego indeksowania. W pierwszej kolejności indeksowane są także witryny zaszyfrowane z pomocą protokołu HTTP/2. Wartość tego rozwiązania została podkreślona podczas wydarzenia I/O Google 2021. Podczas wykładu „Co nowego w wyszukiwarce Google?” John Mueller przekazał wiele istotnych informacji, podkreślając, że indeksowanie stron internetowych dla protokołów HTTP/2 będzie bardziej wydajne i efektywne.
Priorytetem dla Google jest przeglądanie i indeksowanie wersji mobilnej zamiast wersji desktopowej. To oznacza, że jeśli witryna nie jest zoptymalizowana pod kątem urządzeń mobilnych, to może stracić na widoczności i rankingowaniu w wynikach wyszukiwania. W przypadku mobile first indexing, strony prawidłowo zoptymalizowane pod kątem urządzeń mobilnych, mają szasnę na osiągnięcie lepszych wyników w organicznych wynikach wyszukiwania, zarówno na urządzeniach przenośnych, jak i desktopowych.
Dlaczego Google przywiązuje tak dużą wagę do indeksowania mobile first? Według raportu Digital 2023: Global Overview Report – 5,44 miliarda ludzi korzystało z urządzeń mobilnych do przeglądania stron internetowych na początku 2023 roku. To liczba stanowiąca 68% światowej populacji. Przesunięcie priorytetu na strony mobilne ma na celu zapewnienie spójności między tym, co użytkownicy widzą w wynikach wyszukiwania, a tym, co ostatecznie zobaczą na stronie po kliknięciu linku.
Strona powinna być responsywna i dostosowywać się do różnych rozmiarów ekranów, aby zapewnić użytkownikom wygodne i intuicyjne korzystanie z witryny niezależnie od urządzenia, z którego ją przeglądają. na którym się znajdują. Dodatkowo ważne jest, aby treść na stronie mobilnej była równie bogata i użyteczna, jak na wersji desktopowej, aby móc konkurować o lepsze pozycje w wynikach wyszukiwania.
Treści dynamiczne a indeksowanie
Jednym z wyzwań związanych z indeksowaniem treści dynamicznych przez wyszukiwarki jest to, że ich roboty nie zawsze są w stanie skutecznie je interpretować. Wdrożenie takiego rozwiązania powinno być poprzedzone testami, wskazującymi, w jaki sposób boty wyszukiwarek odbierają tego typu treści. W przypadku stron generujących content dynamicznie ( np. z pomocą JavaScript), istnieje kilka sposobów na to, jak poprawić indeksację.
Jednym z podejść do rozwiązania problemów, związanych z dynamicznymi treściami jest zastosowanie renderowania po stronie serwera (inaczej renderyzacja po stronie serwera, Server-Side Rendering, SSR). Polega na generowaniu treści na serwerze i dostarczaniu gotowej oraz zrenderowanej strony do robotów wyszukiwarek. W ten sposób można zyskać pewność, że treści generowane dynamicznie będą widoczne dla robotów wyszukiwarek.
Kolejnym aspektem, który warto wziąć pod uwagę, jest dynamiczne generowanie meta tagów, takich jak tytuł strony i opis. Ważne jest to, by były one dostępne dla robotów wyszukiwarek. Można to osiągnąć poprzez ustawienie odpowiednich wartości meta tagów w kodzie HTML, jeszcze przed ich dynamicznym generowaniem.
Kolejnym istotnym czynnikiem jest używanie standardowych linków i adresów URL. W przypadku stron z treściami generowanymi dynamicznie za pomocą AJAX i JavaScript, ważne jest, aby używać linków i adresów URL, zrozumiałych dla robotów wyszukiwarek. Linki powinny być dostępne w kodzie HTML i prowadzić do konkretnych stron z odpowiednimi treściami. Dzięki temu roboty będą mogły odkryć i zindeksować te strony, a użytkownicy łatwiej odnajdą treści generowane dynamicznie w wynikach wyszukiwania.
Podobnie jak w przypadku standardowych stron, roboty wyszukiwarek muszą „widzieć” wszystkie istotne elementy (treść, obrazy, pliki video oraz powiązania między nimi), dzięki którym ocenią je pod kątem jakości
Jakie adresy URL nie powinny być indeksowane?
Do najczęstszych rodzajów stron, które nie powinny być indeksowane, można zaliczyć:
- Strony logowania i formularze rejestracji – nie powinny być indeksowane, ponieważ zazwyczaj są bezużyteczne dla użytkowników i ich indeksacja może prowadzić do przypadkowego udostępnienia prywatnych danych.
- Strony zawierające duplikaty treści – mogą prowadzić do spadku widoczności witryny w wynikach wyszukiwania i zostać uznane za próbę manipulacji rankingiem.
- Strony z treściami prywatnymi lub chronionymi hasłem – jeśli witryna zawiera strony z treściami, takimi jak dane użytkowników, prywatne dokumenty lub inne poufne informacje, to nie powinna być indeksowana, gdyż może to naruszyć bezpieczeństwo danych.
- Strony o niskiej przydatności – strony o dużej liczbie duplikatów treści, zawierające spam, generowane automatycznie, z niską jakością treści, również nie powinny być indeksowane.
- Wybrane strony w sklepach internetowych – nie należy indeksować m.in. podstron z zamówieniami, koszykiem zakupowym, wewnętrzną wyszukiwarką (choć tu zdarzają się wyjątki), regulaminem, polityką prywatności, polityką cookies, formularzami służącymi do logowania i rejestracji, ulubionymi produktami, zwrotami produktów, filtrowaniem oraz sortowaniem produktów w sklepie.
Podsumowanie
W przypadku wyszukiwarek, takich jak Google czy Bing, indeksowanie jest kluczowym procesem, umożliwiającym skuteczne wyszukiwanie i wyświetlanie wyników użytkownikom. Jeśli dana strona nie zostanie zaindeksowana, nie będzie uwzględniona w SERP, co uniemożliwi jej przyciąganie ruchu organicznego, negatywnie wpływając także na osiąganie przez nią określonych celów biznesowych.